Machine Learning Operations—MLOps—is the discipline that helps organizations move machine learning models from experimentation into stable, scalable, and reliable production systems. In this article, we’ll explore what MLOps is, why it’s needed, and how it solves real-world problems using practical examples.
Why MLOps Matters
Imagine you’re building a fraud detection system for a banking application. The data science team has created an impressive model in a research environment using Python notebooks and historical training data. During development, the model correctly identifies 95% of fraudulent transactions with low false-alarm rates.

However, when the model is deployed into the bank’s production systems, problems begin:
1. Environment Mismatch
The model was built in Python, but the bank’s infrastructure is based on Java for security and performance reasons. If Python isn’t permitted in production, engineers must rewrite the model in Java, often introducing performance regressions.
If the rewritten model now takes 3 seconds to evaluate a transaction, real-time fraud detection becomes impossible.
2. Infrastructure Differences
A model built on a laptop may behave differently in production due to mismatched libraries, resource limits, or cloud configurations (e.g., deploying on Kubernetes clusters with different CPU/memory/GPU constraints).
3. Model Degradation Over Time
After a few weeks in operation, fraud patterns evolve. The original model, trained on older data, begins missing new fraud cases. This data drift reduces accuracy.
4. Lack of Reproducibility
If no one documented how the model was trained—what data was used, what preprocessing steps were applied—engineers cannot reliably retrain or debug it later.
5. Missing Monitoring
The team realizes the model is failing only after customers complain. Without real-time monitoring, performance issues go unnoticed.
How MLOps Solves These Problems
MLOps provides a systematic framework for building, deploying, monitoring, and maintaining machine learning models.
1. Consistent Environments with Containers
Using tools like Docker, teams can package a model with all its dependencies so it runs identically everywhere—on a laptop, on test servers, or in the cloud.
For a fraud detection model, this means consistent and predictable behavior in every environment.
2. Scalable Deployment with Kubernetes
Once containerized, models can be deployed to Kubernetes clusters, such as Amazon EKS. Kubernetes automatically:
-
scales the model during peak usage
-
restarts failing containers
-
ensures high availability
-
handles rolling updates
The entire setup can be defined using Infrastructure as Code tools like Terraform or CloudFormation, ensuring reproducibility.
3. Automated Performance Testing (CI/CD)
Before a model is allowed into production, CI/CD pipelines (GitHub Actions, Jenkins, GitLab CI) run automated tests:
-
unit tests
-
integration tests
-
performance tests (e.g., latency per transaction)
If the fraud model is too slow, the pipeline blocks deployment until it is optimized.
4. Detecting Data Drift
Tools such as TensorFlow Data Validation or Great Expectations continuously compare incoming production data with the training data. When customer behavior changes or new fraud tactics appear, the system quickly flags it.
In advanced setups, pipelines can even trigger automatic retraining with new examples.
5. Full Experiment Tracking
MLOps uses tools like MLflow or DVC to automatically record:
-
datasets used
-
preprocessing steps
-
model parameters
-
training metrics
-
versions of every model build
This makes model building reproducible and auditable.
6. Continuous Monitoring in Production
Dashboards built with Prometheus and Grafana track:
-
accuracy
-
error rates
-
data drift
-
latency
-
model throughput
Alerts notify the team if the model begins missing fraud cases or flagging legitimate transactions.
7. Safe, Zero-Downtime Updates
Tools such as Argo CD can deploy new models through rolling updates. If the new model performs worse, the system automatically rolls back to the previous version.
A Complete MLOps Workflow for Fraud Detection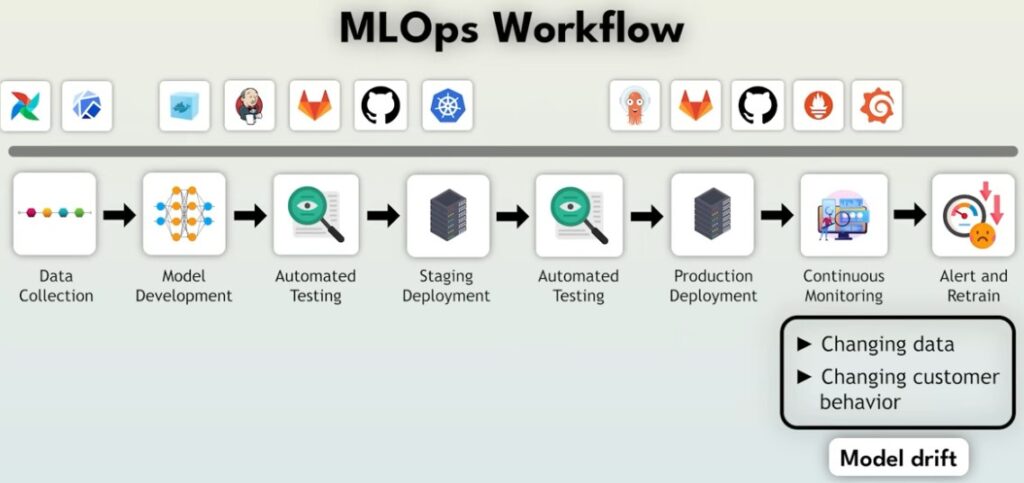
Here’s how a full end-to-end process may look:
-
Data engineers collect and clean transaction data using tools like Airflow or Kubeflow.
-
Data scientists develop models inside standardized Docker environments.
-
CI/CD tools run automated tests for quality and speed.
-
If tests pass, the model is deployed to a staging environment on Kubernetes.
-
Additional tests with real-world data run before production deployment.
-
New models are rolled out safely using GitOps tools such as Argo CD.
-
Prometheus/Grafana monitor the model continuously.
-
Drift detection triggers alerts or automatic retraining if new fraud patterns appear.
Who Should Learn MLOps?
1. Data Scientists
Understanding packaging, CI/CD, and reproducibility makes them far more effective and reduces hand-off friction with engineering teams.
2. DevOps Engineers
They already know CI/CD, cloud infrastructure, and Kubernetes—adding ML concepts (model drift, feature stores, experiment tracking) turns them into valuable MLOps engineers.
3. Engineering Managers
A basic understanding helps with planning, allocating resources, and avoiding critical deployment mistakes.
4. Cloud Engineers
ML workloads require specialized infrastructure:
-
GPUs for training
-
scalable inference services
-
high-throughput storage for large datasets
Cloud engineers who understand ML requirements are significantly more in demand.
Conclusion
MLOps bridges the gap between experimental machine learning models and robust, production-ready AI systems. Just as DevOps revolutionized software development, MLOps is becoming essential for deploying AI at scale.