On average we create about 100 servers for a load supply and about 150 servers for our own service. All these servers need to be created, deleted, configured and launched. For this we use the same tools as on the production to reduce the amount of manual work:
- To create and delete a test environment – Terraform scripts;
- To configure, update and launch – Ansible scripts;
- For dynamic scaling depending on the load – self-written Python scripts.
As we are using Terraform and Ansible scripts, all operations from creating of instances to starting the server are performed in just six commands:
#run the required instances in the aws console ansible-playbook deploy-config.yml #update server versions ansible-playbook start-application.yml #run our application on these servers ansible-playbook update-test-scenario.yml --ask-vault-pass #update the Jmeter script if there were changes infrastructure-aws-cluster/jmeter_clients:~# terraform apply #create a jmeter server to supply load ansible-playbook start-jmeter-server-cluster.yml #run jmeter cluster ansible-playbook start-stress-test.yml #run the test
Dynamic server scaling
At rush hour on production, we can have more than 20K online users at the same time, and at other hours may be 6K. It makes no sense to constantly keep the full volume of servers, so we set up auto-scaling for the board-servers on which the boards open at the moment users enter them, and for API-servers that process API-requests. Now servers are created and deleted only when necessary.
Such a mechanism is very effective in load testing: by default, we can have the minimum number of servers, and at the time of the test they will automatically rise to the amount needed. At the beginning, we can have 4 board servers and at the peak – up to 40. At the same time, new servers are not created immediately, but only after the current servers load. For example, a criterion for creating of new instances may be 50% of CPU utilization. This allows you to not slow down the growth of virtual users in the script and to not create unnecessary servers.
A bonus of this approach is that because of the dynamic scaling we find out how much capacity we need for a different number of users, which we didn’t have on the production yet.
Collection of metrics as on production
There are many approaches and tools for monitoring stress tests, but we went our own way.
We monitor production with a standard stack: Logstash, Elasticsearch, Kibana, Prometheus and Grafana. Our cluster for tests is similar to the product, so we decided to do the same monitoring as on the production, with the same metrics.
There are two reasons for this:
- No need to build a monitoring system from 0, we already have it complete and immediately.
- We additionally test the monitoring of production: if during monitoring of the test we understand that we do not have enough data to analyze the problem, then it will not be enough for production too, when such a problem appears there.
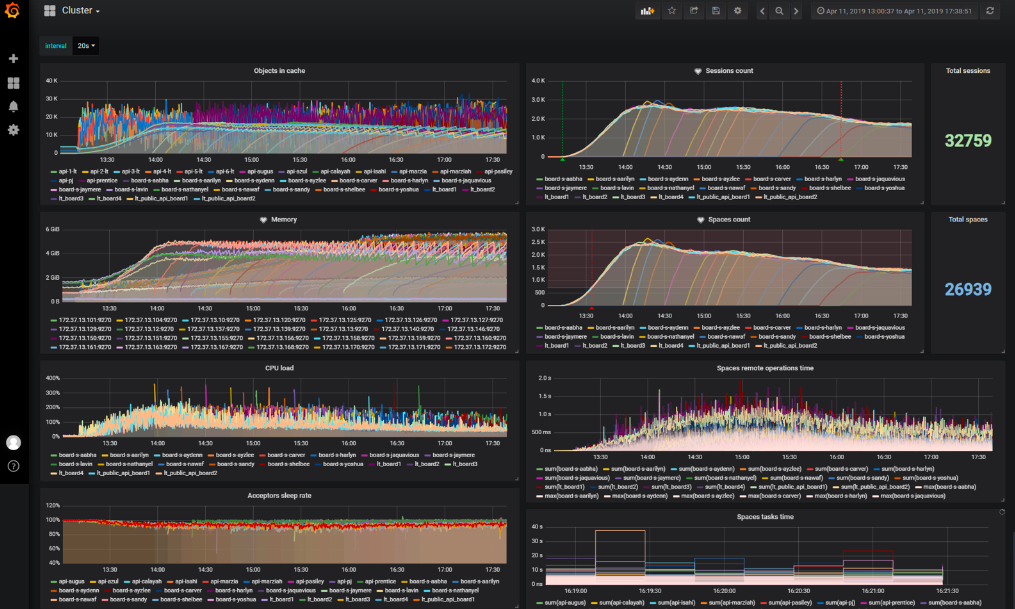
What we show in the reports
- Technical characteristics of the server;
- The script itself, described in words, not code;
- A result that is understandable to all team members, both developers and managers;
- Graphs of the general state of the server;
- Graphs that show a vulnerabilities or what was affected by the optimization, which was checked in the test.
It is important that all results are stored in one place. So it will be convenient to compare them with each other from launch to launch.
Infrastructure as code
In our company responsible for the quality of the product are not QA Engineers, but the whole team. Stress tests are one of the quality assurance tools. Cool if the team understands that it is important to check the changes, which were made under load. To begin to think about it, the team needs to become responsible for the production. Here we are using the principles of DevOps culture, which always have place in our work.
But starting to think about making stress tests is only the first step. The team will not be able to prepare good tests without understanding the production from inside. We encountered such a problem when began to set up the process of making load tests in teams. At that time, the teams had no way to figure out the production in details, so it was difficult for them to work on the design of the tests. There were several reasons: the lack of relevant documentation or one person who would keep the whole picture of the production in head; multiple growth of the development team.
To help teams understand the work of production, we began to use in the development team approach “Infrastructure as code”.
Which problems we have already begun to solve using this approach:
- Everything must be scripted and can be raised at any time. This significantly reduces the recovery time for production in the case of a data center accident and allows you to keep the right amount of relevant test environments;
- Reasonable savings: we deploy environments on Openstack when it can replace expensive platforms like AWS;
- Teams themselves create stress tests because they understand, how the production works;
- The code replaces the documentation, so there is no need to update it endlessly, it is always complete and up to date;
- You do not need a separate expert in a narrow field to solve ordinary problems. Any engineer can figure out the code;
- With a clear production structure, it is much easier to schedule research load tests like chaos monkey testing or long memory leak tests.
We would like to extend this approach not only to the creation of infrastructure, but also to support various tools. For example, the database test, we completely turned into code. Due to this, instead of a pre-prepared site, we have a set of scripts, with which in 7 minutes we get the configured environment in a completely empty AWS account and can start the test. For the same reason, we are now carefully considering Gatling, which the creators are positioning as a tool for “Load test as code”.
The approach to the infrastructure as a code entails a similar approach to testing it and the scripts that the team writes to raise the infrastructure of new features. All of this should be covered by tests. There are also various test frameworks, such as Molecule. There are tools for chaos monkey testing, for AWS there are paid tools, for Docker there are Pumba, etc. They allow you to solve different types of tasks:
- if one of the instances in AWS crashes, will be load on the remaining servers rebalanced or no and if the service will survive from such a sharp request redirection;
- how to simulate the slow operation of the network, its breakage and other technical problems, after which the logic of the service infrastructure should not break.
Summary
- It’s not worth to waste a time on manual orchestration of the test infrastructure, it’s better to automate these actions in order to more reliably manage of all environments, including production;
- Dynamic scaling significantly reduces the cost of production maintaining, large test environment and human factor;
- You don’t have to use a separate monitoring system for tests, it can be taken from production;
- It is important that stress test reports are automatically collected in a single place and have a same view. This will allow to easily compare and analyze changes;
- Stress tests will become a process in the company when teams feel responsible for the production;
- Load tests – infrastructure tests. If the load test was successful, it is possible that it was not compiled correctly. To validate the correctness of the test requires a deep understanding of the production. Teams should be able to independently understand the production structure. We solved this problem using the “Infrastructure as Code” approach;
- Infrastructure preparation scripts also require testing like any other code.