Serverless cloud computing services emerged in 2014 with AWS Lambda, which allowed you to run code without provisioning or managing servers. AWS Lambda is an example of a function as a service (FaaS) where the result of event processing is independent of the server’s memory state and the contents of the local file system. This elastic computing allowed processor, memory, and storage resources to be rapidly scaled up and freed up without the need to plan and take action to handle peak loads.
AWS Lambda was quickly followed by solutions from Microsoft Azure and Google Cloud. Later, cloud providers began to offer other services in a serverless form. This is the latest, new look at cloud services, and in practice, serverless architectures are often several times cheaper due to their scalability than persistent servers designed to perform the same workloads.
What does serverless mean?
Despite the name, serverless does not mean that servers are not being used. You just don’t need to order and maintain dedicated machines as such. There is no need to manage the infrastructure, monitor it, configure it, distribute resources. When a request for code execution comes to a serverless service, the cloud provider will simply allocate a virtual machine or module (a set of containers, usually managed by Kubernetes) specifically for processing it. And when the serverless code completes, the allocated resources are returned to the shared pool. You pay only for the actual server resources spent, depending on the required capacity and the time the process is active.
Serverless functions can call each other (or other services), write information to shared file systems and databases. One of their biggest technical advantages is their incredible scalability. Unlike dedicated servers, which can be overwhelmed by traffic spikes, new serverless pods or virtual machines are simply launched for every new event that needs them. Any traffic peak is passed automatically. And when the resources are no longer needed, they are automatically returned to the pool.
What happens when a module of the right size is not available in the pool when the next request arrives? The cloud provider simply creates a new one. True, there may be some delay in processing the request, up to several seconds. If such a large delay is a problem for your use case, you can pay to have some functions always initialized and ready to respond. AWS, for example, calls this service Provisioned Concurrency. Other cloud providers have different names, but the meaning is the same: they rely on preloading certain functions to reduce their response latency to hundreds of milliseconds, even in a pinch. According to Amazon itself, this is ideal for implementing interactive services, including web servers for mobile devices, delay-sensitive microservices, or synchronous APIs.
Serverless functions and services usually show very high stability, as providers allocate excess computing power distributed physically to process them. And there is no difference which of the machines will process the code. The probability of losing everything when one data center burns down tends to zero. In addition to serverless services from providers, there are many different independent platforms and SDKs available for building serverless applications. Including Kubeless, Pulumi, OpenFaaS, OpenWhisk and Serverless Framework.
What is the difference between serverless databases
According to Jim Walker of Cockroach Labs, creator of CockroachDB, a serverless database operates on nine basic principles:
The almost complete absence of manual server management Automatic flexible scaling of applications and services Built-in fault tolerance and inherently fault-tolerant service Always in stock + instant access Consumption based service billing engine Possibility to survive in case of any failure Geographical scale, distribution Transaction guarantees The Elegance of Relational SQL
While principles 1-5 are basic, they can be applied to any serverless service. And principles 6-9 only apply to global SQL databases.
The traditional way to connect to most databases is to establish a persistent TCP connection from the client to the server. But for serverless databases, this is not suitable: setting up a TCP connection to process each function can take too much time. Ideally, a client should connect to a serverless endpoint almost instantly (less than 100ms) and receive a response to its request within a second. To ensure this, some serverless databases (such as Amazon Aurora Serverless) support HTTP (HTTPS) connections and work on the connection pooling needed to support scaling and creating near-instantaneous connections.
How Serverless Databases Can Save You Money
Traditional databases should be designed for the maximum expected query load. This means that the money for its support is spent “to the maximum”. If the database can be scaled up and down without the need for data migration, you can save money by increasing the CPU load during periods of high load and decreasing it during periods of low load.
In a serverless architecture, the client pays not for the reserved (to the maximum) capacity, but for specific read, write, delete operations, or the active operation time of the modules. That allows you to easily pass the peak periods, and not lose extra money during the “stagnation”. Also, this approach allows you to more accurately calculate the economics of the project in the face of the impossibility of accurately predicting its scale. The big pain of business is removed – payment for capacity during downtime. You can pay only for those calculations that have actually been carried out.
Serverless databases usually don’t need resizing at all. You don’t pay for capacity until the request is sent, and when it is sent, you get as many resources as you need to fulfill your request. Then the fee is charged for the used power, multiplied by the time the database is active. You only pay for the compute you need, and depending on the size and nature of your traffic, this can be a huge economic benefit. According to Amazon, you can save up to 90% on your database maintenance cost with Aurora Serverless.
Serverless architectures benefit from significant reductions in operational costs, complexity, and development time. But in return, you increase your dependence on specific providers and may not get the full package of services you are used to due to the relative youth of the entire ecosystem.
When are serverless databases suboptimal?
Recommended use cases for serverless databases include variable or unpredictable workloads, enterprise database fleet management, software as a service applications, and scalable databases split across multiple servers.
But serverless also has its downsides. So, due to the lack of standardization, any serverless features you use with one vendor will be implemented slightly differently by another vendor. And if you want to change providers, you will almost certainly need to update your operational tools and probably modify your code (for example, to suit a different FaaS interface). It may even need to change the design or architecture, since competing service providers have significant differences in implementation.
And of course, if there are no peak loads and periods of attenuation, you lose the main advantage of serverless. Databases with predictable and constant load are easier and cheaper to handle by deploying traditional servers. Even those databases that are heavily loaded on weekdays and then idle on weekends and holidays are usually better handled by servers rather than serverless systems – provided that you shut down the servers for every weekend and holidays. Despite the evolution of serverless, this approach has generally remained more cost-effective.
But serverless computing is still a fairly new, unexplored world. The existing shortcomings are gradually being eliminated here, the ecosystem is developing, and the advantages of the technology are becoming more and more obvious.
Serverless Database Examples
Some, such as MongoDB Atlas, offer serverless features only in preview format. But most of the leaders, following Amazon, came out with their own serverless solutions. So there are plenty to choose from.
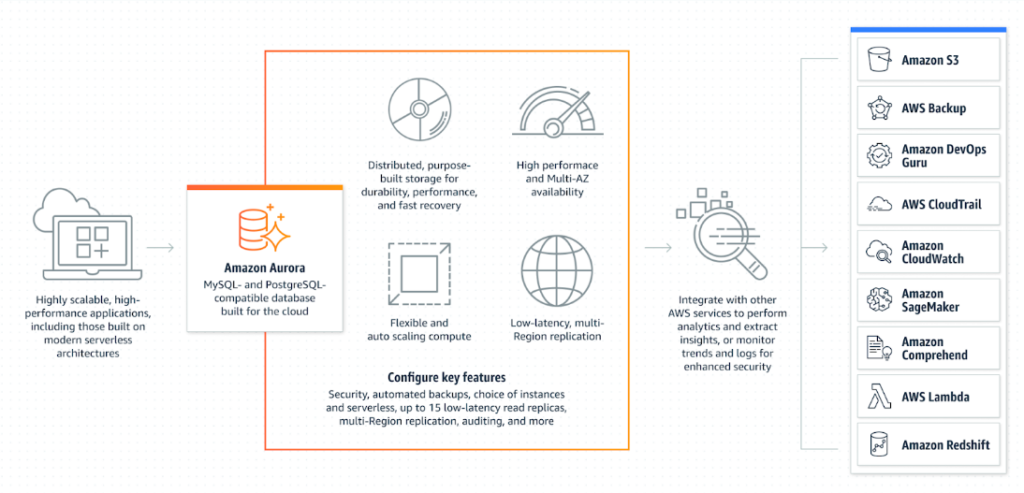
An auto-scaling configuration available on demand for Amazon Aurora. Assumes automatic connection, disconnection and scaling of resources depending on the needs of the application. Allows you to run a database in the cloud, eliminating the need to manage its resources manually. It is enough to create the address of the database server, specify the desired limits for changing database resources and connect the necessary applications.
Compatible with MySQL and PostgreSQL. It is part of the Amazon Relational Database Service (RDS), so there are integrations with MariaDB, Oracle, and SQL Server.
Resources are billed on a per-second basis. However, you can quickly switch between Standard and Serverless configurations in the Amazon RDS management console.
Amazon DynamoDB
A fully managed, serverless NoSQL database designed to run high performance applications of any scale. Offers built-in security, continuous backup, automatic multi-region replication, in-memory caching, and convenient data export tools.
Azure SQL Database Serverless
This is a version of Microsoft SQL Server that automatically scales computing resources based on your workload. Billing is based on the number of calculations used per second. At the same time, the platform automatically suspends the operation of databases during periods of inactivity, and then bills only for their storage. When activity is restored, the database operation is automatically resumed. Like AWS, Azure offers 1 million calls and 400,000 GB-seconds for free every month. Further – 20 cents for each subsequent million calls
Azure Synapse Serverless
Allows you to use T-SQL to query data from a data lake in Azure, rather than allocating resources for it in advance. You only pay for completed requests, and the cost depends on the amount of data processed by each request.
CockroachDB Serverless
A free option currently in beta testing on Cockroach Labs’ PostgreSQL compatible cloud. Can use highly available clusters on AWS or Google Cloud in a multi-tenant configuration. Limits for free use: 250 million requests per month and 5 GB of storage.
Fauna
A flexible, developer-friendly transactional database delivered as a secure and scalable serverless cloud API with native GraphQL. Combines the flexibility of NoSQL systems with the relational query and transactional capabilities of SQL databases. Supports both Fauna query language and GraphQL.
Google Cloud Firestore
A serverless, document-oriented NoSQL database that is part of Google Firebase. Unlike SQL Database, there are no tables or rows in Cloud Firestore. Instead, you store data in documents that are organized into collections. Each document contains a set of key-value pairs.
Cloud Firestore is optimized for storing large collections of small documents. All documents should be stored in collections. Documents can contain nested collections and nested objects, which can include primitive fields like strings and complex objects like lists.
The DBMS is designed as a replacement for the Realtime Database with the ability to quickly query and scale. Coupled with native SDKs and easy authentication, Google expects this option to carve a niche for mobile and web apps that plan to stay within scaling limits.
PlanetScale
MySQL compatible serverless database platform powered by Vitess. Vitess is a database clustering system for scaling out MySQL (as well as Percona and MariaDB). Vitess also supports Slack, Square, GitHub, YouTube, and more.
Oracle Cloud Functions
One of the very fresh serverless platforms, the first implementation is less than two years old. An advantageous option if you do not have a lot of requests. The first 2 million function calls per month are free, then you pay $0.2 for each subsequent million (for comparison, MongoDB will have $0.3 for 5 million). Features integrate with Oracle Cloud Infrastructure, platform services, and SaaS applications. Since Cloud Functions is based on the open source Fn project, developers can create applications that can be easily ported to other cloud and local environments.
Redis Enterprise Cloud
A fully managed serverless database that runs on AWS, Azure, and Google Cloud. Enterprise modules can extend Redis from a simple key-value data structure store to a powerful JSON-enabled tool with artificial intelligence.
Redis Enterprise performs automatic resharding and rebalancing while maintaining low latency and high throughput for transactional workloads. The Redis on Flash (RoF) feature allows you to place frequently accessed data in memory to further reduce the latency of calling it. But there is only 30 MB of free storage offered here.
As you can see, serverless databases offer highly scalable cloud storage without requiring you to do anything up front. All of them offer to pay only for what you use, and many, in an attempt to lure users, are even completely free for small volumes – especially if you are satisfied with the limited maximum request processing speed.
Serverless databases are great for small mobile and web applications, for MVP testing, for startups. The ability to deliver solutions to market quickly and cheaply, and then scale them based on actual demand, provides a huge competitive advantage.
At the same time, serverless solutions are not for everyone, so be wary of those who say they will replace all of your existing architectures. Difficult debugging, monitoring issues, dependency on a particular service provider, and the possible increase in latency as the number of requests increases, means that for large and established systems, with hundreds of millions of database accesses daily, traditional solutions will be more preferable.