Today I want to share ideas on how to implement data synchronization between different storages. Such tasks sometimes arise at work, for example, when deleting user data under the General Data Protection Regulation ( GDPR ) and the California Consumer Privacy Act ( CCPA ).
These laws are not difficult to follow if you maintain an average site or a small product. Most likely, in these cases, one of the popular frameworks is used, and the user table is stored in a well-known database (MySQL, PostgreSQL).
Got a request to delete all user data? Not a problem! Delete a row in the table, and you’re done. Apart from logs, error traces, backups and other interesting places. We assume, of course, that everything is set up correctly and the personal data of users are hidden with asterisks or something else.
In our case, the situation is slightly more complicated, created more than 50 tools, and all of them are supported by dozens of development teams. A few years ago, each team moved the code of their tool to a separate microservice, we get user data from the user service. But one way or another, we store all the information that is necessary for the tool to work.
Thus, we faced the question: how to synchronize the data stores of the microservice and the user service.
Synchronization methods
1. Periodically, we can check with the user service via the REST API :
$ curl ''
[
{
"id": 42,
"registration_date": "2015-03-08 01:00:00",
"email": "[email protected]",
"name": "John",
...
You can even immediately send a list of users for verification, but this is somehow strange. User deletions do not occur often enough to make DDoS attacks on the service.
2. Event-driven architecture is another approach to solve our problem. Two entities appear here: a message generator (Publisher) and a subscriber (Subscriber), which reads the event channel (topic).
You can abandon the subscriber entity and set an API endpoint for all microservices, to which the user service would send requests when a new event occurs. In this case, you need to agree on API interaction protocols: REST, JSON-RPC, gRPC, GraphQL, OpenAPI, or whatever else there may be. In addition, it is necessary to keep the configuration files of the microservices, where to send requests, and most importantly: what to do when the request does not reach the microservice after the third repetition?
The advantages of this architecture:
- Asynchronous automatic synchronization of data stores.
- The load on the user service increases slightly, so we only add an asynchronous event recording to the event channel.
- Synchronization of data from various storages is separate from the (already loaded) user service.
Minuses:
- The minus arising from the first plus: data inconsistency between user services and other microservices.
- No transactions: simple messages are generated.
- Keep in mind that messages in the queue can be repeated.
In general, all the listed advantages and disadvantages are rather conditional and depend on specific tasks. There are no universal solutions, in my opinion. On this topic, it will be useful to read about the CAP theorem .
Implementing an event-driven architecture using Pub/Sub as an example from Google Cloud
There are many alternatives: Kafka, RabbitMQ, but our team chose a solution from Pub / Sub Google Cloud, since we already use Google Cloud, and it is easier to configure those or Kafka or RabbitMQ.
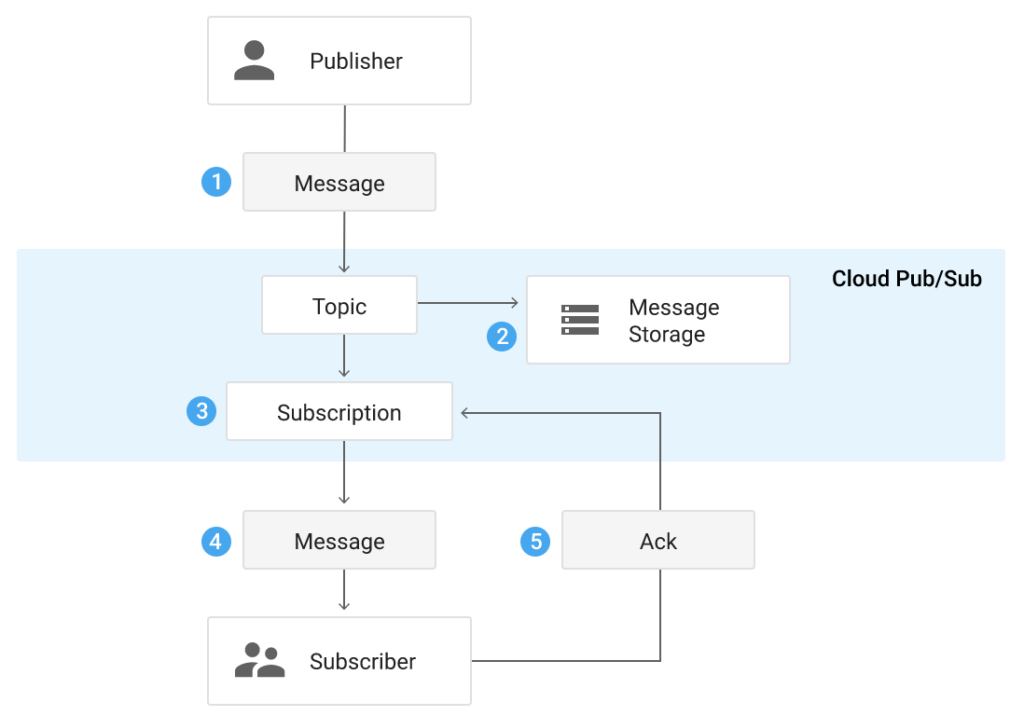
In our case, Publisher is a user service, and Subscriber is a microservice of the command of a particular tool. Subscriber’ov (as well as Subscription) can be any number. Given that Semrush has a large number of tools and commands, the subscriber queue is ideal for us:
- Everyone reads the queue with the frequency necessary for him.
- Someone can set an endpoint, and topic will call it immediately when a message appears (if you need to receive new messages instantly).
- Even exotic options, such as rolling back the tool database from an old backup, do not cause problems: just reread the messages from the topic (it is worth mentioning that you need to take into account the idempotency of queries, and perhaps you should read the topic not from the beginning, but from some point ).
- Subscriber provides a REST protocol, but to simplify development, there are also clients for various programming languages: Go, Java, Python, Node.js, C#, C++, PHP, Ruby.
You can use one topic with different messages, for example, we have several types of messages: changing the user, changing the user’s access, and so on.
Implementation example
Creating a topic and subscriber:
gcloud pubsub topics create topic
gcloud pubsub subscriptions create subscription --topic=topicMore details can be found in the documentation .
Creating a user to read a topic:
gcloud iam service-accounts create SERVICE_ACCOUNT_ID \
--description="DESCRIPTION" \
--display-name="DISPLAY_NAME"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:SERVICE_ACCOUNT_ID@PROJECT_ID.iam.gserviceaccount.com" \
--role="pubsub.subscriber"
gcloud iam service-accounts keys create key-file \
[email protected]The downloaded key in json format must be saved and forwarded to the service. Don’t forget about the rules for handling secrets! Everyone knows about this, and a little more my colleagues from the Security team. Let me know in the comments if you find the topic useful and interesting for our next article.
The user for publishing messages is created in the same way, except for the role: –role=”pubsub.subscriber” → –role=”pubsub.publisher”.
For example, let’s take one of our microservices running on Python with Celery. For messages from the user service, there is a scheme described using Protocol Buffers.
import json
import os
import celery
from google.cloud import pubsub_v1
from google.oauth2 import service_account
from user_pb2 import UserEventData
PUBSUB_SERVICE_ACCOUNT_INFO = json.loads(os.environ.get('PUBSUB_SERVICE_ACCOUNT', '{}'))
PUBSUB_PROJECT = 'your project'
PUBSUB_SUBSCRIBER = 'subscription'
@celery.shared_task
def pubsub_synchronisation() -> None:
credentials = service_account.Credentials.from_service_account_info(
PUBSUB_SERVICE_ACCOUNT_INFO, scopes=['']
)
with pubsub_v1.SubscriberClient(credentials=credentials) as subscriber:
subscription_path = subscriber.subscription_path(PUBSUB_PROJECT, PUBSUB_SUBSCRIBER)
response = subscriber.pull(request={"subscription": subscription_path, "max_messages": 10000})
ack_ids, removed_user_ids = [], []
for msg in response.received_messages:
user_event_data = UserEventData()
user_event_data.ParseFromString(msg.message.data)
removed_user_ids.append(user_event_data.Id)
ack_ids.append(msg.ack_id)
# Here you can do everything with removed users :)
subscriber.acknowledge(request={"subscription": subscription_path, "ack_ids": ack_ids}) And we run the task every five minutes, since deleting users is not such a frequent operation:
CELERY_BEAT_SCHEDULE = {
'pubsub_synchronisation': {
'task': 'tasks.pubsub_ubs_synchronisation',
'schedule': timedelta(minutes=5)
},An example of posting messages to a topic in Python is implemented in a similar way. Use PublisherClient instead of SubscriberClient and call the publish method instead of pull.
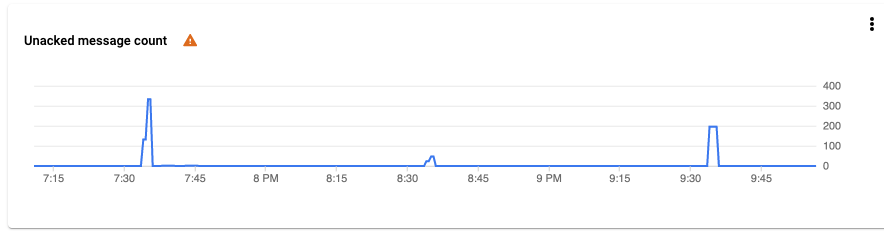
As a result, there is synchronization of deletion of users to comply with GDPR / CCPA laws. For example, at 7:37 a.m., there was a mass deletion of accounts from the user account storage service. At 7:40 the task to get data from Topic worked. All tasks are selected, the local database is synchronized.
In the article, we looked at two architectures and settled on an event-driven one. It is likely that in your case it will be possible to get by with manual synchronization.