KUBERNETES
Kubernetes (K8s) is software for automating the deployment, scaling, and management of containerized applications. Supports major containerization technologies (Docker, Rocket) and hardware virtualization.
WHY YOU NEED KUBERNETES
Kubernetes is required for continuous integration and software delivery (CI/CD, Continuous Integration / Continuous Delivery), which corresponds to the DevOps approach. Thanks to the “packaging” of the software environment in a container, the microservice can be deployed very quickly on the production server (production), safely interacting with other applications. The most popular technology for such virtualization at the operating system level is Docker, whose package manager (Docker Compose) allows you to describe and run multi-container applications.
However, if you need a complex order for launching a large number of such containers (from several thousand), as is the case in Big Data systems, you will need a tool for managing them – an orchestration tool. This is considered the main purpose of Kubernetes.
Kubernetes (K8s) is software for automating the deployment, scaling, and management of containerized applications. Supports major containerization technologies (Docker, Rocket) and hardware virtualization.
WHY YOU NEED KUBERNETES
Kubernetes is required for continuous integration and software delivery (CI/CD, Continuous Integration/Continuous Delivery), which corresponds to the DevOps approach. Thanks to the “packaging” of the software environment in a container, the microservice can be deployed very quickly on the production server (production), safely interacting with other applications. The most popular technology for such virtualization at the operating system level is Docker, whose package manager (Docker Compose) allows you to describe and run multi-container applications [2].
However, if you need a complex order for launching a large number of such containers (from several thousand), as is the case in Big Data systems, you will need a tool for managing them – an orchestration tool. This is considered the main purpose of Kubernetes.
At the same time, Kubernetes is not just a container orchestration framework, but a whole container management platform that allows you to run many tasks in parallel, distributed over thousands of applications (microservices) located on various clusters (public cloud, own data center, client servers, etc.) .).
However, Kubernetes cannot be called a classic PaaS solution: K8s consists of several modules that can be combined in various ways while retaining key functionality (application deployment, scaling, load balancing, logging, etc.).
HISTORY OF K8S DEVELOPMENT
Initially, the Kubernetes project was developed by Google Corporation, one of the largest Big Data companies, for its internal needs in the Go programming language. In mid-2014, the source codes for the project were published. The first ready release of the system was released on July 21, 2015 (version 1.0). In the second half of 2015, Google Corporation, together with the Linux Foundation, organized a special Cloud Native Computing Foundation (CNCF), to which Kubernetes was transferred as an initial technological contribution.
KUBERNETES ARCHITECTURE
Kubernetes is arranged according to the master/slave principle when the cluster management subsystem is the leading element, and some components control the slave nodes. A node is a physical or virtual machine on which application containers run. Each node in the cluster contains tools for running containerized services, such as Docker [2], as well as components for centralized management of the node.
Pods are also deployed on the nodes – basic modules for managing and launching applications, consisting of one or more containers. At the same time, on one node for each pod, resource sharing, inter-process communication, and a unique IP address within the cluster are provided. This allows applications deployed on the pod to use fixed and predefined port numbers without the risk of conflict. To share multiple containers deployed on the same Pod, they are combined into a volume (volume) – a shared storage resource.
In addition to pods, the following Kubernetes components also run on slave nodes:
Kube-proxy is a combination of a network proxy and a load balancer, which, as a service, is responsible for routing incoming traffic to specific containers within a pod on the same node. Routing is provided based on the IP address and port of the incoming request.
Kubelet, which is responsible for the execution status of the pods on the node, monitors the correctness of the execution of each running container.
Pod management is implemented through the Kubernetes API, command-line interface (Kubectl), or specialized controllers (controllers) – processes that take the cluster from the actual state to the desired one, operating with a set of pods, defined using label selectors. Label selectors are queries that allow you to get a link to the desired control object (node, sub, container).
The following elements work on the master component:
Etcd is a lightweight distributed NoSQL key-value DBMS that is responsible for the consistent storage of cluster configuration data.
API Server – A key component of the control subsystem that provides a REST-style application programming interface (in JSON format over HTTP protocol) and is used for external and internal access to Kubernetes functions. The API server updates the state of the objects stored in etcd, allowing its clients to manage the distribution of containers and load between the nodes of the system.
a scheduler that regulates the distribution of load across nodes by selecting an execution node for a particular pod based on the node’s resource availability and the pod’s requirements.
controller manager (controller manager) – a process that executes the main Kubernetes controllers (DaemonSet Controller and Replication Controller) that interact with the API server, creating, updating, and deleting the resources they manage (pods, service entry points, etc.)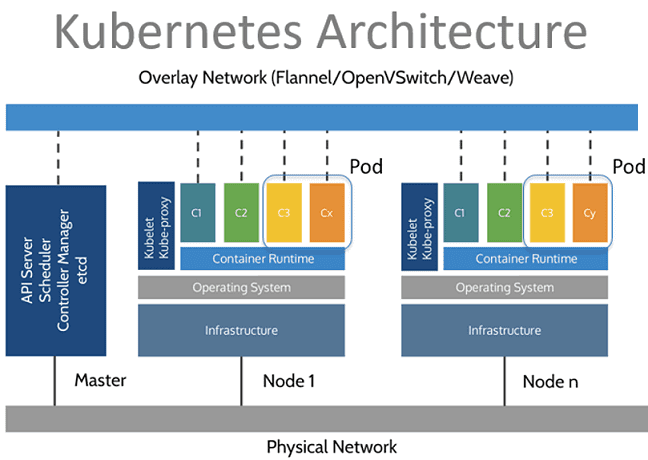
HOW KUBERNETES WORKS
According to the concept of containerization, containers contain executable services, libraries, and other resources necessary for the operation of these applications. Access to the container from the outside is realized through an individually assigned IP address. Thus, in Kubernetes, a container is a software component at the lowest level of abstraction. For inter-process communication of several containers, they are encapsulated in pods.
The task of Kubernetes is to dynamically allocate the resources of a node between the pods that run on it. To do this, on each node, using the built-in Kubernetes cAdvisor internal monitoring agent, continuous collection of performance and resource usage data (CPU, RAM, file, and network system loads) is continuously collected.
What is especially important for Big Data projects, is Kubelet, a component of Kubernetes running on nodes, automatically provides start, stop, and management of application containers organized in pods. When it detects problems with a particular pod, Kubelet tries to redeploy and restart it on the node.
Similar to HDFS, the most popular distributed file system for Big Data solutions implemented in Apache Hadoop, in a Kubernetes cluster, each node constantly sends diagnostic messages (heartbeat messages) to the master. If, based on the content of these messages, or in the absence of them, the master detects a failure of any node, the Replication Controller control subsystem process tries to restart the necessary pods on another node that is working correctly.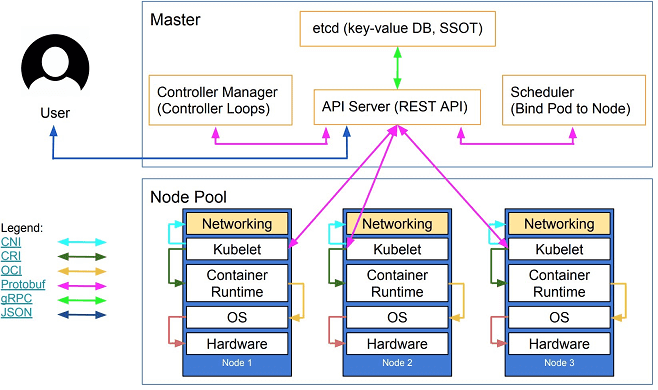
EXAMPLES OF USING KUBERNETES
Since K8s are designed to manage many containerized microservices, it is not surprising that this technology brings the maximum benefit to Big Data projects. For example, Kubernetes is used by the popular dating service Tinder, the telecommunications company Huawei, the world’s largest online service for finding car companions BlaBlaCar, the European Center for Nuclear Research (CERN) and many other companies working with big data and in need of tools for rapid and fault-tolerant application deployment.
In connection with the digitalization of enterprises and the spread of the DevOps approach, the demand for ownership of Kubernetes is growing in domestic companies. As the review of vacancies from the HeadHunter recruiting platform showed, in 2019 this technology is almost mandatory for a modern DevOps engineer and Big Data developer.