Sharding
What to do when the data stops getting on one server? There are two standard zoom mechanisms:
-
- Vertical when we just add memory and disks to this server. This has its limits – in terms of the number of cores per processor, the number of processors, and the amount of memory.
- Horizontal, when we use many machines and distribute data between them. Sets of such machines are called clusters. To place data in a cluster, they need to be sharded – what means, for each record, determine which server it will be located on.
A sharding key is a parameter by which data is distributed between servers, for example, a client or organization identifier.
Imagine that you need to record data about all the inhabitants of the Earth in a cluster. As a shard key, you can take, for example, the person’s birth year. Then 116 servers will be enough (and every year it will be necessary to add a new server). Or you can take as a key the country where the person lives, then you will need approximately 250 servers. Still, the first option is preferable, because the person’s birth date does not change, and you will never need to transfer data about him between the servers.
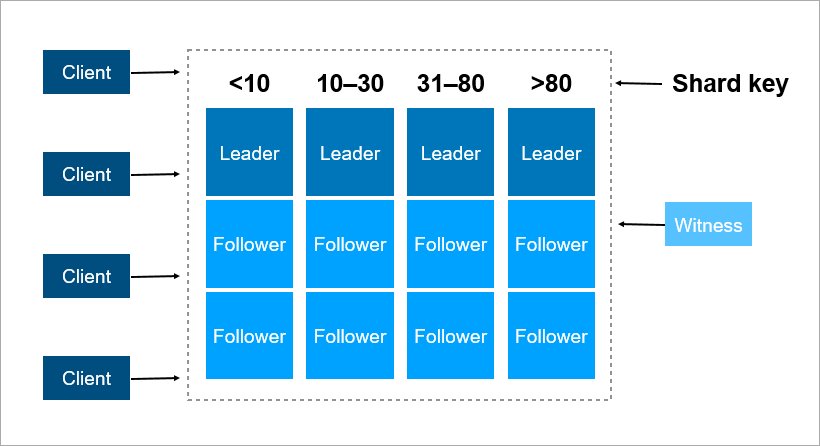
As a sharding key, it is better to choose data that rarely changes. However, far from always an applied task makes this easy to do.
Consensus in the cluster
When there are a lot of machines in the cluster and some of them lose contact with the others, then how to decide who stores the latest version of the data? Just assigning a witness server is not enough, because it can also lose contact with the entire cluster. In addition, in a split brain situation, several machines can record different versions of the same data – and you need to somehow determine which one is the most relevant. To solve this problem, people came up with consensus algorithms. They allow several identical machines to come to a single result on any issue by voting. In 1989, the first such algorithm, Paxos, was published, and in 2014, Stanford guys came up with a simpler Raft to implement. Strictly speaking, in order for a cluster of (2N + 1) servers to reach consensus, it is enough that it has at the same time no more than N failures. To survive 2 failures, the cluster must have at least 5 servers.
Relational DBMS Scaling
Most databases that developers are used to working with support of relational algebra. The data is stored in tables and you need to join the data from different tables by JOIN operation. Lets consider an example of a database and a simple query to it.
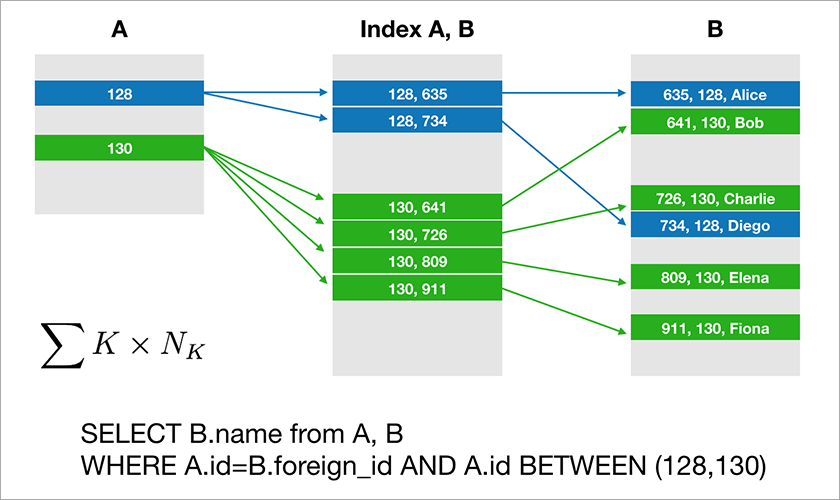
Assume A.id is a primary key with a clustered index. Then the optimizer will build a plan that will most likely first select the necessary records from table A and then take the appropriate links to the records in table B from a suitable index (A, B). The execution time of this query grows logarithmically from the number of records in the tables.
Now imagine that the data is distributed across four servers in the cluster and you need to execute the same query:
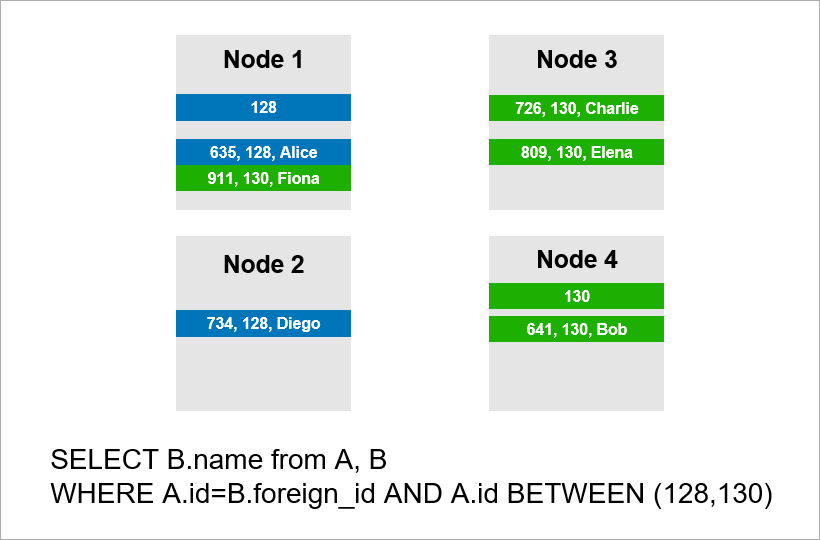
If the DBMS doesn’t want to view all the records of the entire cluster, then it will probably try to find records with A.id equal to 128, 129, or 130 and find the appropriate records for them from table B. But if A.id is not a shard key, then the DBMS in advance cannot know which server the data of table A is on. You will have to contact all the servers anyway to find out if there are A.id records suitable for our condition. Then each server can make a JOIN inside itself, but this is not enough. You see, we need the record on node 2 in the sample, but there is no record with A.id = 128? If nodes 1 and 2 will do JOIN independently, then the query result will be incomplete – we will not receive some of the data.
Therefore, to fulfill this request, each server must turn to everyone else. Runtime grows quadratically on the number of servers. (You are lucky if you can shard all tables with the same key, then you don’t need to go around all the servers. However, in practice this is unrealistic – there will always be queries where fetching is not based on the shard key.)
Thus, JOIN operations scale fundamentally poorly and this is a real problem of the relational approach.
NoSQL approach
Difficulties with scaling classic DBMSs have led people to come up with NoSQL databases that don’t have a JOIN operation. No joins – no problem. But there are no ACID properties, but they did not mention this in marketing materials. Quickly found craftsmen who test the strength of various distributed systems and post the results publicly. It turned out that there are scenarios when the Redis cluster loses 45% of the stored data, the RabbitMQ cluster – 35% of messages, MongoDB – 9% of records, Cassandra – up to 5%. And we are talking about the loss after the cluster informed the client about the successful save. Usually you expect a higher level of reliability from the chosen technology.
Google has developed the Spanner database, which operates globally around the world. Spanner guarantees ACID properties, Serializability and more. They have atomic clocks in data centers that provide accurate time, and this allows you to build a global order of transactions without the need to forward network packets between continents. The idea of Spanner is that it is better for programmers to deal with performance problems that arise with a large number of transactions than crutches around the lack of transactions. However, Spanner is a closed technology, it does not suit you if for some reason you do not want to depend on one vendor.
The natives of Google developed an open source analogue of Spanner and named it CockroachDB (“cockroach”, which should symbolize the survivability of the database).
As a result, today there are relational databases that scale well only vertically, what is expensive. And there are NoSQL solutions without transactions and without ACID guarantees (if you want ACID, write by your owm).
How to make mission-critical applications in which data does not fit on one server? New solutions appear on the market, and about one of them – FoundationDB – we will tell you more in the next articles.