Significant performance metrics require a deep understanding of the various potential bottlenecks that can arise in today's servers and data center infrastructures in which they reside.
Overview of the standard platform for NVMe drives
Storage systems rely heavily on standard x86 server platforms, and RAIDIX is no exception. Therefore, in terms of performance, we will consider a regular server that supports NVMe drives. As a rule, two-socket platforms are used on Intel processors or single-socket platforms on AMD processors. A block diagram of an Intel Xeon server-based platform is shown in the figure below, and potential performance bottlenecks are circled and numbered.
Let's take a look at the potential bottlenecks of the PCIe 3.0 based platform, as these platforms are less balanced in terms of component bandwidth and NVMe drives. The general principles will remain unchanged for platforms with PCIe 4.0, although they were initially more optimized for using NVMe drives and high-speed network interfaces.
A typical Intel Scalable Gen 2 processor-based server is a two-socket system with interprocessor connections. Each socket typically provides 48 PCIe 3.0 lanes, and all cores share a coherent L3 cache. This architecture is called NUMA (Non-Uniform Memory Access). In Intel processors, the two sockets are connected by Ultra Path Interconnect (UPI) channels, which carry any traffic directed to PCIe, DRAM, or cache memory associated with another socket. AMD's interconnect is called AMD Infinity Fabric, but since AMD processors have significantly more PCIe lanes (128), single-processor platforms are more often used.
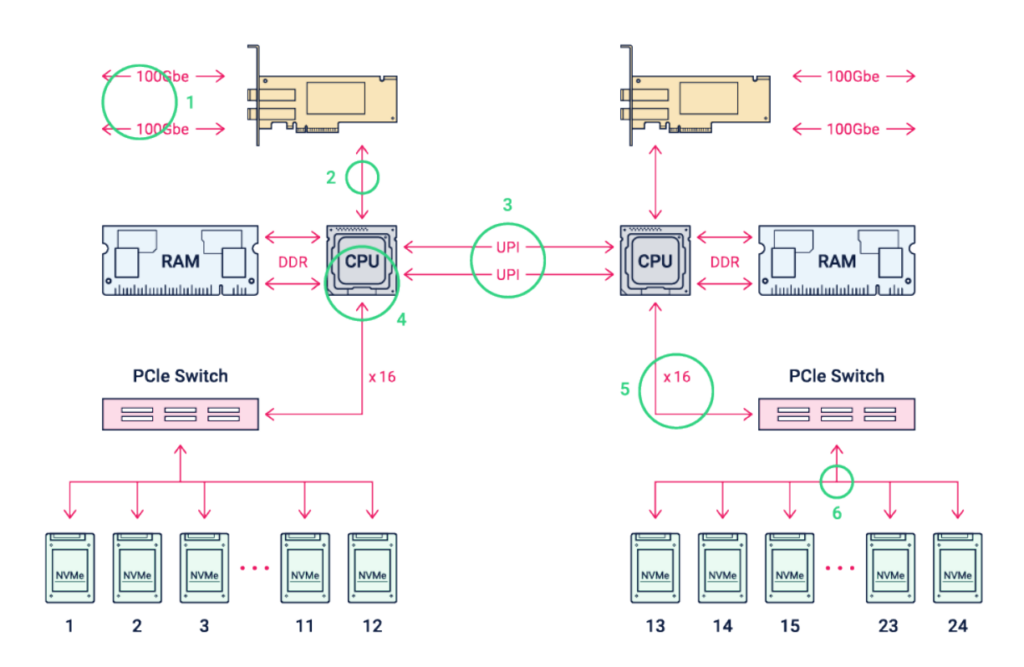
True, most often about 40 PCIe 3.0 lines from one socket are allocated to drives and slots for expansion cards, since some of the lines are used for devices integrated on the motherboard, such as network adapters, BMC / IPMI, etc. In the diagram above, of the 80 available PCIe 3.0 lanes, two NICs use 32 lanes, leaving 48 to serve 24 NVMe drives. Since enterprise NVMe drives typically have four PCIe lanes, PCIe switches are required to connect 96 NVMe (24×4) lanes to the processors. As shown in the picture above, each CPU connects to one of two network cards and half of the NVMe drives. Commands coming to one NIC, but directed to drives connected to another socket, will have to go through the UPI channel.
The main bottlenecks of NVMe platforms
The bandwidth for each numbered block diagram of a dual-socket NVMe platform is shown in the table below, and each is discussed in detail.
|
# |
Element |
Theoretical maximum throughput (number of channels – throughput) |
Actual maximum |
|
1 |
100GbE |
1 – 12.5GB/s |
1 – 11.4GB/s |
|
2 |
Network card connections to PCIe 3.0 x16 |
32GB/s |
|
|
3 |
UPI (dual 10.4GT\s) |
2 – 41.6GB/s |
2 – 41.6GB/s |
|
4 |
CPU |
Depends on the software used |
Depends on the software used |
|
5 |
PCI switch PCIe 3.0 x16 |
16 – 16GB/s |
16GB/s |
|
6 |
SSD Interface PCIe 3.0 x4 |
4 – 4GB/s |
4GB/s |
|
7 |
Flash SSD |
Depends on hard drive |
Depends on hard drive |
Bottleneck # 1: network
NICs used in servers with NVMe drives are most often single or dual-port 100GbE. There may be others, but Ethernet and Infiniband now have the highest speeds, but since Ethernet is more common, we will consider it. 100 GbE has a net payload of about 11.4 GB / s per port, so the dual-port NIC is nominally capable of running at 22.8 GB / s.
Layer 3-4 networking protocols (such as RoCE v2 or TCP / IP) impose performance constraints beyond that of the data link (Ethernet) layer, and they can be significant. Table 1 takes into account the protocol overhead that utilizes the bandwidth of the channel. It is important to note, however, that it does not include the additional bandwidth costs associated with the time it takes for the network stack to process each packet. This time can be significant and depends on the specific choice of the network card and switching equipment, as well as on the selected protocol.
RoCE v2 is an RDMA protocol that uses a zero-copy architecture, that is, when transferring data using RoCE v2, unnecessary copies between the application and the operating system buffers are eliminated. RoCE v2 typically provides bandwidths close to those shown in the table.
TCP / IP implementations are very different – the tradeoff between offloading and loading, as well as the choice of where the driver should be implemented – in the kernel or in userspace (kernel-bypass technologies such as DPDK, etc.) – all these affect performance. making it difficult to generalize. Currently, TCP / IP is noticeably less efficient as it requires more CPU resources than RoCE v2, although the gap will narrow over time as network vendors add hardware off-load to TCP / IP.
The last potentially significant factor that is not included in this analysis is the impact of network congestion and the cost of recovering bandwidth from network errors (eg, packet loss).
Bottleneck # 2: connecting a network card
Many 100 GbE NICs have a PCIe 3.0 x16 slot. For single-port network cards based on PCIe 3.0, the network bandwidth and connection slot are quite well balanced – 11.4 and 14.5 GB / s, respectively. However, for dual-port cards, connecting to the PCIe 3.0 x16 bus becomes a bandwidth limitation, since it rests on the bus and is only able to operate in half-duplex mode at a speed of 14.5 GB / s.
Bottleneck # 3: processor
The best advantage of NVMe is that it delivers superior performance by eliminating the SAS HBA bottleneck by connecting directly to the CPU. But the performance of NVMe is affected by the number of cores and the frequency of the processor. So, according to the results of tests of NVMe drives, the best performance is achieved when the ratio of two computing cores to one NVMe drive with a CPU frequency of at least 2.5GHz.
Bottleneck # 4: interprocessor connections
Modern server processors are typically designed with a Non-Uniform Memory Architecture (NUMA). This means that the latency for accessing certain memory cells and I / O channels is not the same for all cores, since some of the traffic must go through interprocessor connections, be it Intel Ultra Path Interconnect or AMD Infinity Fabric.
As shown in Table 1, NUMA channels are designed with very high bandwidth in relation to I / O capabilities, both from the network interface side and from the NVMe side. But, nevertheless, it is recommended to load the disk subsystem from the same processor to which the network card is connected.
Bottleneck # 5: PCIe Switch
Intel-based dual-socket server processors typically do not have enough PCIe 3.0 lanes in the processors to handle a full set of 24 or more NVMe drives. Platforms based on these processors often include two internal PCIe switches that act as PCIe extenders.
The example shows a platform where 12 NVMe x4 drives are connected via a PCIe switch to 16 PCIe lanes. This connection makes the platform balanced in terms of IO flow from clients to NVMe drives since both the network cards and 12 NVMe drives are connected to PCIe 3.0 x16. Often these two places define the overall bandwidth limit of the platform.
Bottleneck # 6: connecting an NVMe drive
Most enterprise PCIe Gen3 NVMe SSDs have four lanes for host connection. Such an interface provides a theoretical bandwidth of about 3.6 GB / s in each direction, which is more than enough for work and will not be a bottleneck.
Bottleneck # 7: NVMe storage
Unlike other platform components discussed in the article, an NVMe drive has fundamentally different performance characteristics for reading and writing. The flash memory stick is divided into two or four parts, each of which can simultaneously process one read, write or delete operation. SSD performance varies based on design, available space, and capacity.
Typically, the NVMe drive itself will not be a performance bottleneck, but multiple devices will be forced to share the PCIe bandwidth of the switch, which can affect the final performance.
Conclusion
We looked at seven bottlenecks that determine the final performance of an NVMe server platform. In each of the points, we analyzed the problems that will help you understand what to look for in servers in order to get the most out of NVMe drives.