Application deployment in a Kubernetes multi-cluster environment is one of the hottest topics. The approach allows you to expand the possibilities for scaling services, ensure traffic locality due to the geographical location of clusters, increase the reliability and fault tolerance of the deployed solution, and also eliminate the risks of mutual influence of applications within the same cluster.
However, managing the lifecycle of such federated applications is quite difficult. Under the cut, I propose to consider the key tasks in the framework of creating federated services and build a reference multi-cluster deployment architecture that can be implemented in different cloud infrastructures.
We build the architecture of a multicluster service
To illustrate the multi-cluster approach, we will use a simple system that consists of two applications. APP 1 processes external traffic from users of this system and in turn calls APP 2 to process requests, such as storing information in a database.
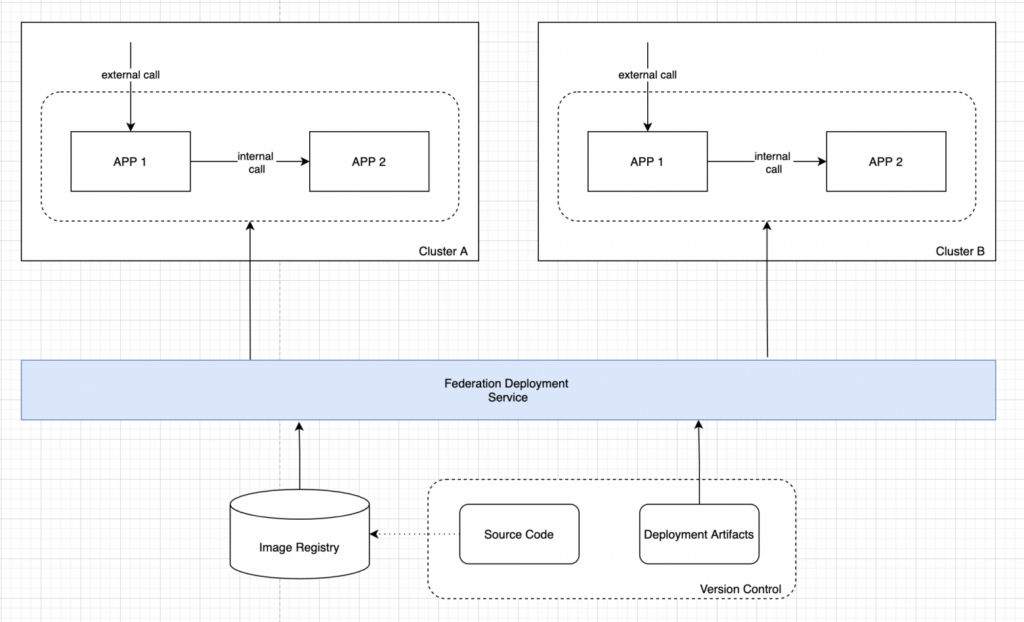
The source code of our applications, as well as artifacts for deployment (Kubernetes resources, Helm charts, or, for example, OpenShift templates), are all placed in the version control system. Additionally, the source code is available in a form prepared for deployment – ready-made docker images are placed in the corporate image repository.
Now that we have everything we need to deploy the application, let’s think about what is needed in order to make this service multi-cluster.
The first task to be solved is application deployment. When we have one cluster, this is easily solved. Just use kubectl apply or more advanced templating approaches like helm or the OpenShift templating engine.
However, in conditions of multiple clusters, this approach does not scale. It is not enough to simply run the installation sequentially with different environments, since in this case we cannot automatically ensure cluster consistency at the application lifecycle management level.
With this problem in mind, we formulate the requirements for solving the first problem. We need a specialized service for automated multi-cluster deployment that:
- uses standard artifacts (application image and templating manifests) for deployment;
- deploys the application according to a given list of clusters, ensuring that changes are rolled back according to a given set of criteria (for example, in case of unsuccessful deployment to one of the clusters);
- provides continuous change delivery with automatic maintenance of deployment consistency in a multi-cluster environment.
Now let’s reflect this service in the architecture and look at the intermediate scheme.
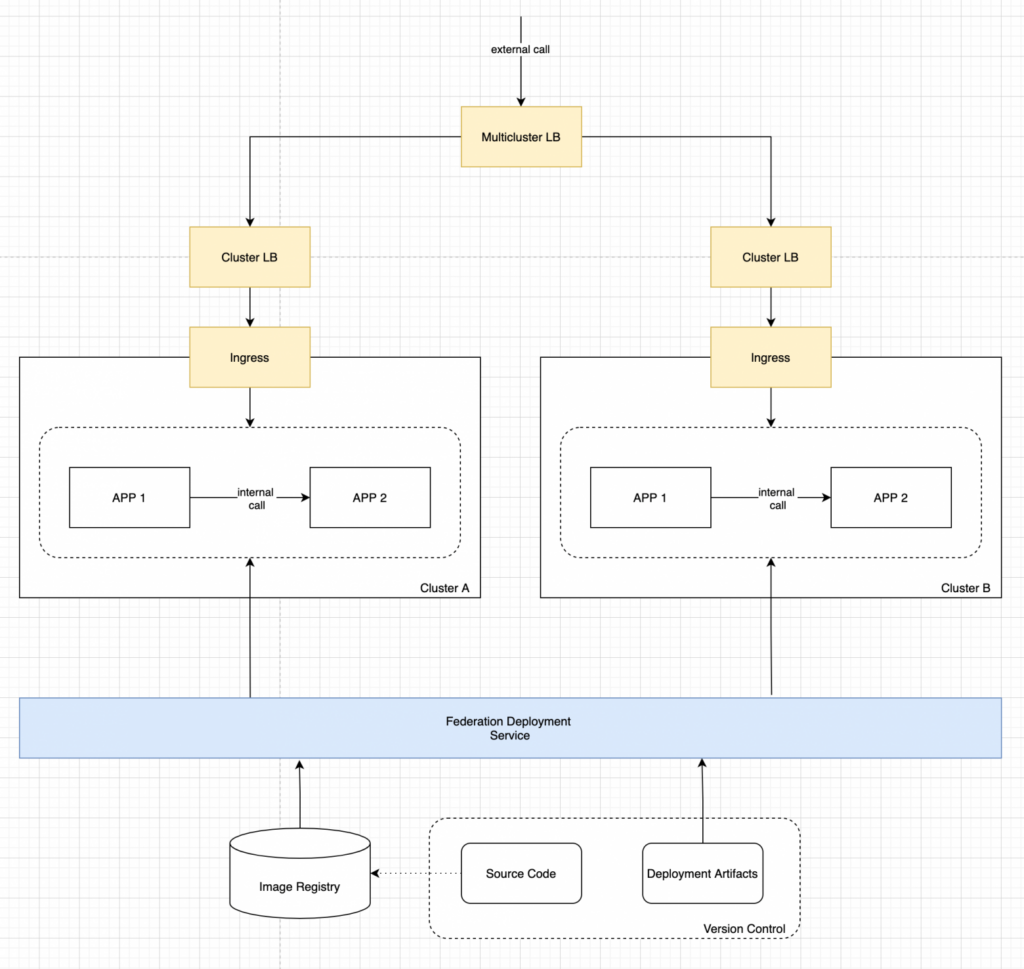
The second task is to provide balancing and failover for external requests.
The “single-cluster” approach starts by using an Ingress Controller at the Kubernetes edge. Additionally, a load balancer is needed, which will ensure the distribution of traffic between the cluster nodes where the Ingress Controller instances are running. Such a balancer can be provided by a cloud provider for managed clusters, or it can be configured manually for on-premise installations.
In the case of a multi-cluster installation, this approach is scalable, however, an additional balancing layer is required to distribute traffic already between clusters. As a result, we get something like this:
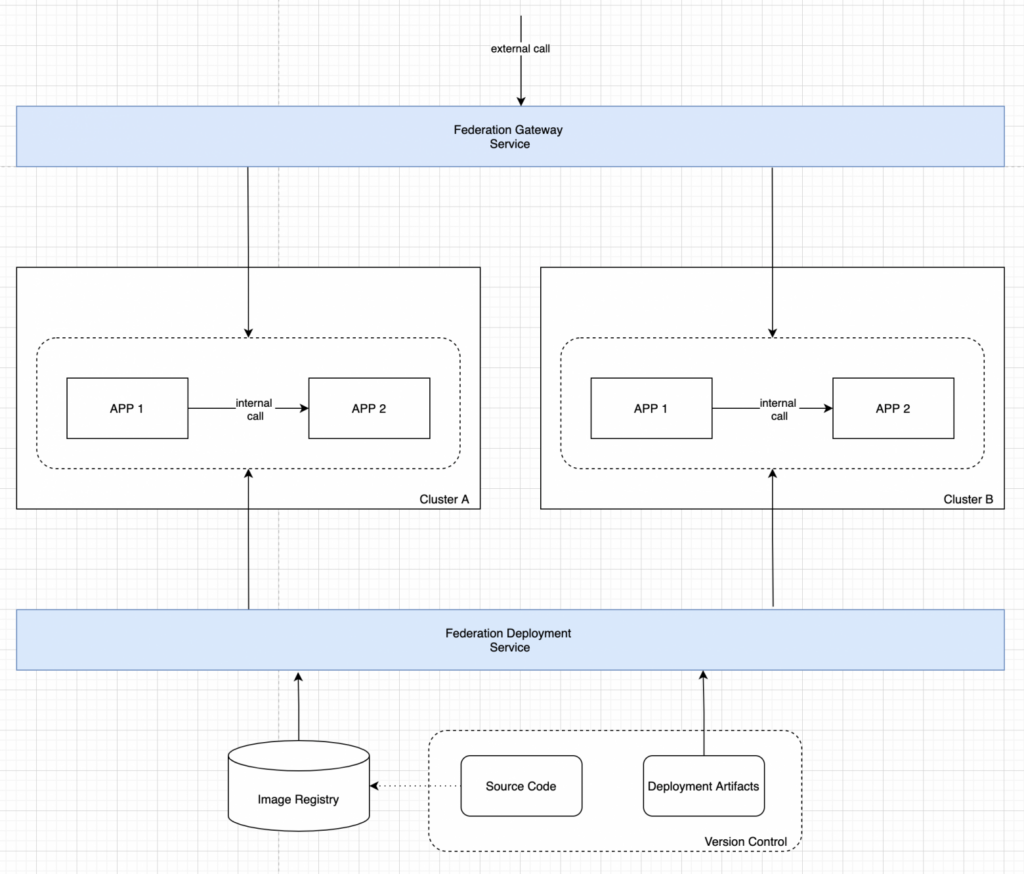
This scheme solves the problem, but is opaque and difficult for the end user. In addition to the standard set of actions for publishing an application, you need to remember that the service is multicluster and you need at least additional configuration of rules at the Multicluster LB level.
To overcome this shortcoming, you can use a special service that encapsulates all the details of the application’s multi-cluster topology. This service:
- provides the user with a single resource for publishing applications in a multi-cluster topology;
- ensures the generation of all necessary network resources within all clusters for balancing and failover of external requests;
- provides continuous change delivery with automatic consistency maintenance in a multi-cluster environment.
Thus, after solving the second task, our architecture looks like in the figure below:
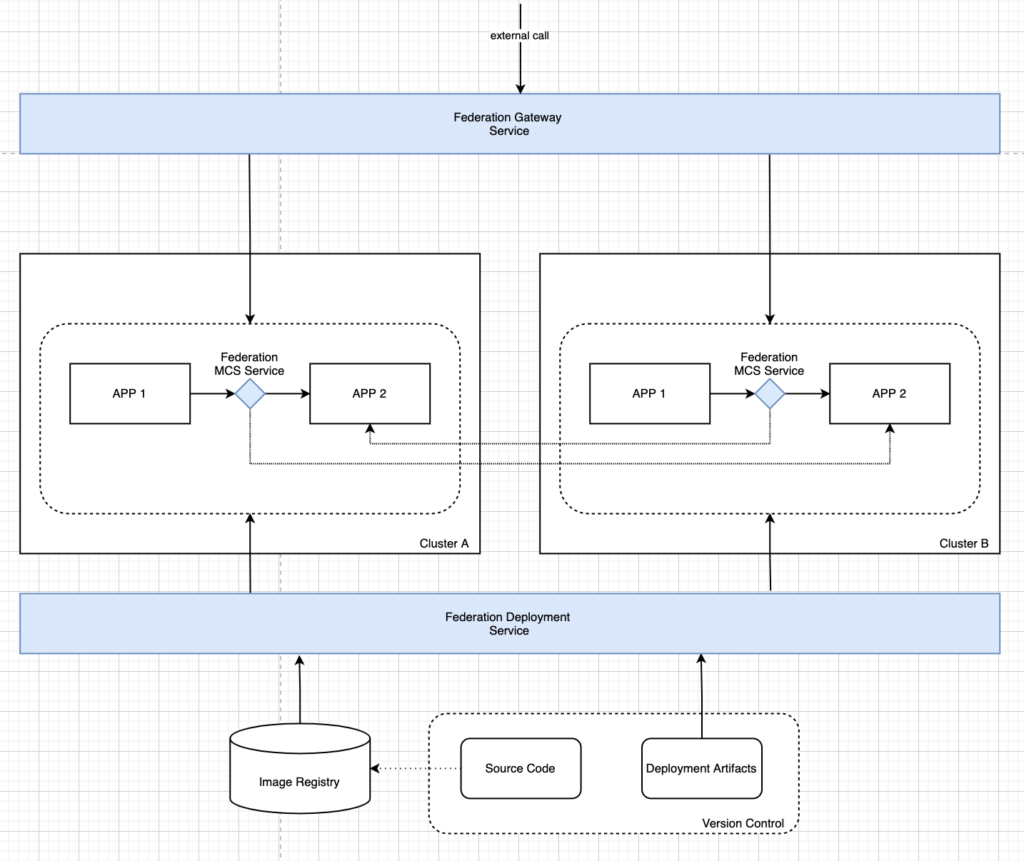
As part of the third task, we need to provide balancing and failover for internal calls in our system. The difficulty is that we cannot publish internal services in the same way as external ones, but it must be possible to make network calls between clusters. In addition, this capability must be transparent to applications: multi-cluster network calls follow the same rules as intra-cluster calls.
Thus, we need a service that:
- provides the ability to publish services from remote clusters in the current one, while remote services are available for calling in the same way as local ones;
- in a situation where a remote service has instances in the current cluster, the union of remote and local instances is ensured within a single callable address;
- for remote services, including those with local instances, balancing and failover are provided according to the specified rules. For example, if local instances of a remote service are unavailable, traffic is switched to remote instances in other clusters.
Taking into account the solution of the third problem, the general architecture looks like the one shown in the figure below.
And finally, within the fourth task, it is important not to forget about the visibility of our application. Logs, metrics, and trace data are extremely important when building microservice systems, and in a multi-cluster deployment, the degree of criticality of this functionality increases significantly.
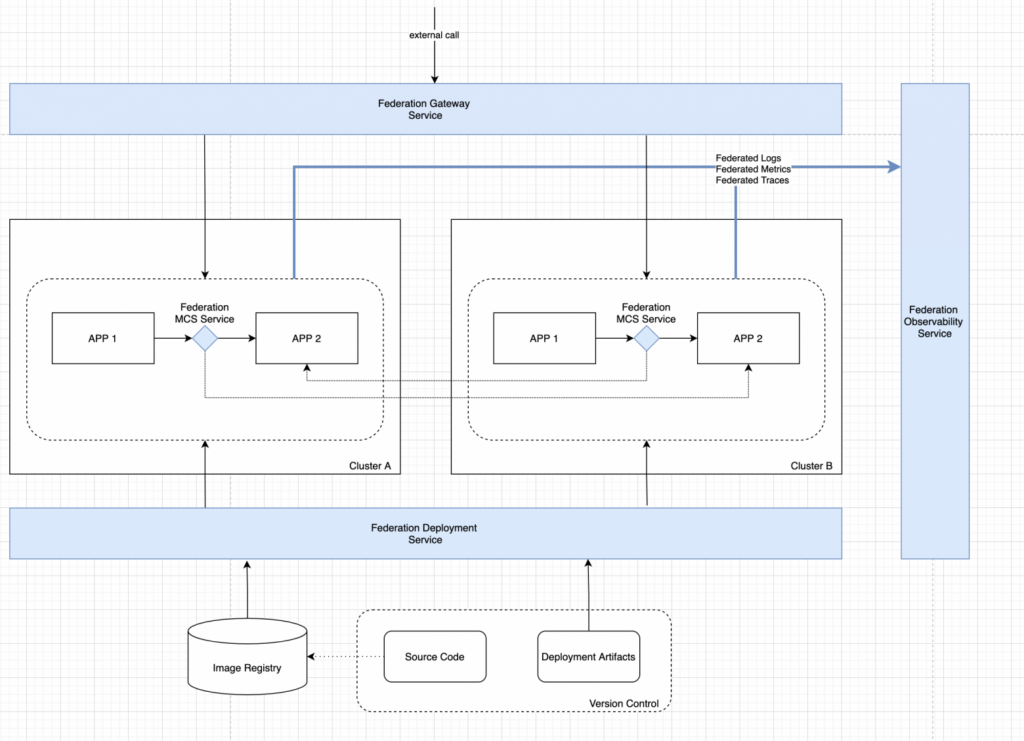
To ensure a sufficient level of visibility, we need a service that:
- aggregates application logs, trace data and monitoring data (metrics) taking into account the multi-cluster deployment topology;
- provides unified access to aggregated data.
As a result, we get the finished architecture of the multicluster service:
We implement the architecture
We have considered typical tasks that need to be solved for a multi-cluster application deployment scheme in Kubernetes, and received a reference architecture for a multi-cluster application.
I deliberately made all services in this architecture abstract. You can find a specific implementation of each of them from your cloud infrastructure provider or implement everything yourself in a private cloud.
And this architecture can be easily implemented based on Platform V Synapse products . This will allow you not to waste resources, not be tied to a specific cloud service and concentrate solely on business logic.
Platform V Synapse is a cloud-native decentralized integration platform for import substitution of any corporate service buses. It is part of Platform V, a cloud platform for developing business applications that has become the basis for digitalization.
Synapse is built on a modern technology stack and uses advanced open source and cloud native technologies: Envoy, Kafka, Flink, Ceph, Kiali, Docker and others.
Consists of 6 key modules:
- Synapse Service Mesh – reliable integration and orchestration of microservices in the cloud;
- Synapse Nerve – secure transfer of file information between systems and microservices in the cloud, with built-in tools for visualization, monitoring and data analysis;
- Synapse EDA – streaming event processing;
- Synapse AI – predictive traffic management enriched with artificial intelligence and machine learning;
- Synapse AppSharding – implementation of horizontal scaling for databases that do not support sharding out of the box;
- Synapse API Management – Publication, access control, and API usage analytics.