This article is first of all, for those who are just beginning their journey through the study of Kubernetes. Also, this material will be useful for engineers who are thinking of moving from a monolith to microservices. Everything described is our own experience, including the transfer of several projects from a monolith to Kubernetes. It is possible that some parts of the publication will be interested also for experienced engineers.
List and destination of hosts
All the nodes of our cluster will be located on virtual machines with a preinstalled Debian 9 stretch system with the kernel 4.19.0-0.bpo.5-amd64. For virtualization, we use Proxmox VE.
| Name | IP адрес | Comment | CPU | MEM | DISK1 | DISK2 |
|---|---|---|---|---|---|---|
| master01 | 10.73.71.25 | master node | 4vcpu | 4Gb | HDD | — |
| master02 | 10.73.71.26 | master node | 4vcpu | 4Gb | HDD | — |
| master03 | 10.73.71.27 | master node | 4vcpu | 4Gb | HDD | — |
| worknode01 | 10.73.75.241 | work node | 4vcpu | 4Gb | HDD | SSD |
| worknode02 | 10.73.75.242 | work node | 4vcpu | 4Gb | HDD | SSD |
| worknode03 | 10.73.75.243 | work node | 4vcpu | 4Gb | HDD | SSD |
It is not necessary to use exactly such configuration of machines, but we still advise you to adhere to the recommendations of the official documentation and increase the amount of RAM to at least 4GB. Looking ahead, we’ll say that with a smaller number, we faced problems in the work of CNI Callico
Ceph is also quite demanding in terms of memory and disk performance.
List and versions of software

Starting from version 1.14, Kubeadm stopped supporting API version v1alpha3 and completely switched to API version v1beta1, which it will support in the near future, so in this article we will only talk about v1beta1.
So, we believe that you have prepared the machines for the kubernetes cluster. They are all accessible to each other over the network, have an Internet connection and a “clean” operating system.
For each installation step, we will clarify on which machines the command or block of commands is executed. All commands will execute from the root-user, unless otherwise specified.
All configuration files, as well as a script for their preparation, are available for download on github (https://github.com/rjeka/kubernetes-ceph-percona).
So, let’s begin.
Kubernetes cluster HA scheme
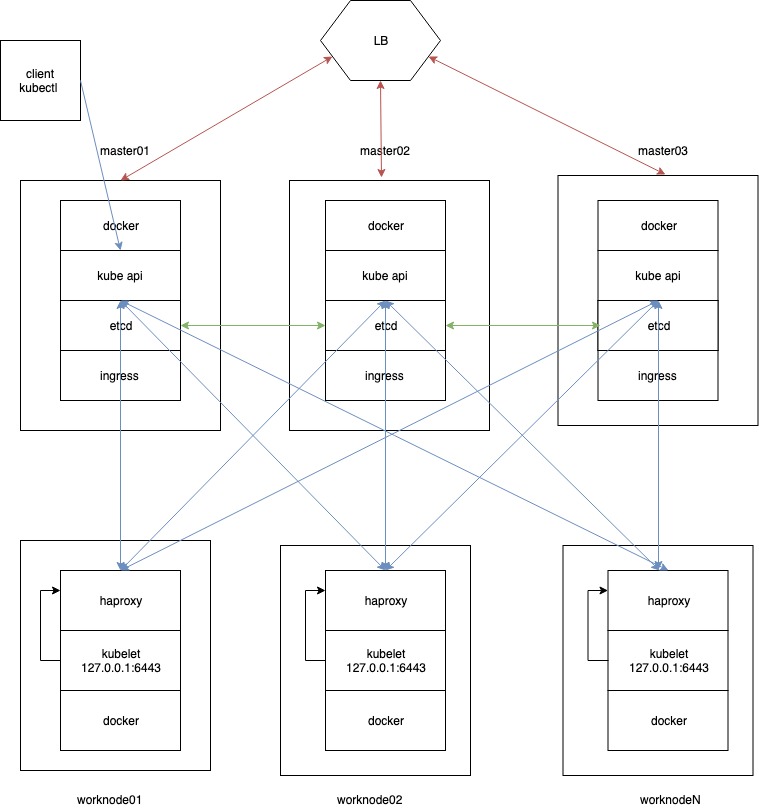
An approximate scheme of the HA cluster. The artists of us are so-so, to be honest, but we’ll try to explain everything in the easiest way, without particularly delving into theory.
So, our cluster will consist of three master nodes and three worker nodes. On each kubernetes master node will work etcd (green arrows on the scheme) and kubernetes service parts; let’s call them generically – kubeapi.
Through the etcd master cluster, nodes exchange the state of the kubernetes cluster. We will indicate the same addresses as entry points of the ingress controller for external traffic (red arrows on the scheme)
On the worker nodes, works kubelet, which communicates with the kubernetes api server via haproxy installed locally on each worker node. As the server api address for kubelet, we will use the localhost 127.0.0.1:6443, and haproxy on roundrobin will divide requests on the three master nodes, it will also check the availability of the master nodes. This scheme will allow us to create HA, and in case of failure of one of the master nodes, worker nodes will directly send requests to the two remaining master nodes.
Before starting work
Before starting work on each node of the cluster, we will install the packages, which we will need for work:
apt-get update && apt-get install -y curl apt-transport-https git
Copy the repository with configuration templates to the master nodes:
sudo -i git clone https://github.com/rjeka/kubernetes-ceph-percona.git
Check that the ip address of the hosts on the masters matches the one on which the kubernetes API server will listen:
hostname && hostname -i master01 10.73.71.25
and like this for all master nodes.
Be sure to disable SWAP, otherwise kubeadm will show an error.
[ERROR Swap]: running with swap on is not supported. Please disable swap
You can disable it with the command:
swapoff -a
Remember to comment in / etc / fstab
Fill out the create-config.sh file
To automatically fill out the configs needed for installing of the kubernetes cluster, we uploaded a small script create-config.sh. You need to fill in it literally 8 lines. Indicate the IP addresses and hostname of your masters. And also specify etcd tocken, or just don’t change it. We will give below that part of the script in which you need to make changes.
#!/bin/bash ####################################### # all masters settings below must be same ####################################### # master01 ip address export K8SHA_IP1=10.73.71.25 # master02 ip address export K8SHA_IP2=10.73.71.26 # master03 ip address export K8SHA_IP3=10.73.71.27 # master01 hostname export K8SHA_HOSTNAME1=master01 # master02 hostname export K8SHA_HOSTNAME2=master02 # master03 hostname export K8SHA_HOSTNAME3=master03 #etcd tocken: export ETCD_TOKEN=9489bf67bdfe1b3ae077d6fd9e7efefd #etcd version export ETCD_VERSION="v3.3.10"
OS kernel update
This step is optional, since the kernel will need to be updated from the back ports, and you do this at your own risk. Perhaps you will never encounter this problem, and if you do, then you can update the kernel even after deploying kubernetes. In general, you decide.
A kernel update is required to fix the old docker bug, which was fixed only in the linux kernel version 4.18. A bug was – the periodic stop of the network interface on the kubernetes nodes with the error:
waiting for eth0 to become free. Usage count = 1
After installing the OS, we had the kernel version 4.9.
uname -a Linux master01 4.9.0-7-amd64 #1 SMP Debian 4.9.110-3+deb9u2 (2018-08-13) x86_64 GNU/Linux
On each machine for kubernetes we execute:
Step # 1
Add back ports to the source list:
echo deb http://ftp.debian.org/debian stretch-backports main > /etc/apt/sources.list apt-get update apt-cache policy linux-compiler-gcc-6-x86
echo deb http://ftp.debian.org/debian stretch-backports main > /etc/apt/sources.list apt-get update apt-cache policy linux-compiler-gcc-6-x86
Step # 2
Package installation:
apt install -y -t stretch-backports linux-image-amd64 linux-headers-amd64
Step # 3
Reboot:
reboot
Check that everything is OK.
uname -a Linux master01 4.19.0-0.bpo.5-amd64 #1 SMP Debian 4.19.37-4~bpo9+1 (2019-06-19) x86_64 GNU/Linux
Preparing Nodes. Installing of Kubelet, Kubectl, Kubeadm, and Docker
Installing of Kubelet, Kubectl, Kubeadm
We put on all nodes of the cluster, according to the documentation of kubernetes.
apt-get update && apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl apt-mark hold kubelet kubeadm kubectl
Install Docker
Install Docker according to the instructions from the documentation:
apt-get remove docker docker-engine docker.io containerd runc apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common curl -fsSL https://download.docker.com/linux/debian/gpg | apt-key add - apt-key fingerprint 0EBFCD88 add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable" apt-get update apt-get install docker-ce docker-ce-cli containerd.io
Installing of Kubelet, Kubectl, Kubeadm and Docker using ansible:
git clone https://github.com/rjeka/kubernetes-ceph-percona.git cd kubernetes-ceph-percona/playbooks vim masters.ini
In the masters group, register the ip of masters.
In the workers group, write the ip of the working nodes.
#If sudo with password ansible-playbook -i hosts.ini kubelet.yaml -K ansible-playbook -i hosts.ini docker.yaml -K #Если sudo безпарольный ansible-playbook -i hosts.ini kubelet.yaml ansible-playbook -i hosts.ini docker.yaml
If for some reason you do not want to use Docker, you can use any CRI.
ETCD Installation
We will not go deep into theory, but shortly: etcd is an open-source distributed key-value storage. etcd is written on GO and used in kubernetes in fact, as a database for a cluster state storing.
etcd can be installed in many ways. You can install it locally and run as a daemon, run it in docker containers or even install as a kubernetes pod. You can install manually or using kubeadm (we haven’t tried this method). It can be installed on cluster machines or individual servers.
We will install etcd locally on the master nodes and run as a daemon through systemd, as well as consider installing in docker. We use etcd without TLS, if you need TLS refer to the documentation of etcd or kubernetes itself.
On all masters: (on the working nodes of the cluster, this step is not necessary)
Step # 1
Download and unpack the etcd archive:
mkdir archives cd archives export etcdVersion=v3.3.10 wget https://github.com/coreos/etcd/releases/download/$etcdVersion/etcd-$etcdVersion-linux-amd64.tar.gz tar -xvf etcd-$etcdVersion-linux-amd64.tar.gz -C /usr/local/bin/ --strip-components=1
Step # 2
Create a configuration file for ETCD:
cd .. ./create-config.sh etcd
The script takes the value etcd as an input, and generates a config file in the etcd directory. After the script runs, the finished config file will be located in the etcd directory.
For all other configs, the script works on the same principle. It takes some input and creates a config in a specific directory.
Step # 3
Run the etcd cluster and check its performance
systemctl start etcd
Check the daemon’s health:
systemctl status etcd
● etcd.service - etcd
Loaded: loaded (/etc/systemd/system/etcd.service; disabled; vendor preset: enabled)
Active: active (running) since Sun 2019-07-07 02:34:28 MSK; 4min 46s ago
Docs: https://github.com/coreos/etcd
Main PID: 7471 (etcd)
Tasks: 14 (limit: 4915)
CGroup: /system.slice/etcd.service
└─7471 /usr/local/bin/etcd --name master01 --data-dir /var/lib/etcd --listen-client-urls http://0.0.0.0:2379,http://0.0.0.0:4001 --advertise-client-urls http://10.73.71.25:2379,http://10.73.71.
Jul 07 02:34:28 master01 etcd[7471]: b11e73358a31b109 [logterm: 1, index: 3, vote: 0] cast MsgVote for f67dd9aaa8a44ab9 [logterm: 2, index: 5] at term 554
Jul 07 02:34:28 master01 etcd[7471]: raft.node: b11e73358a31b109 elected leader f67dd9aaa8a44ab9 at term 554
Jul 07 02:34:28 master01 etcd[7471]: published {Name:master01 ClientURLs:[http://10.73.71.25:2379 http://10.73.71.25:4001]} to cluster d0979b2e7159c1e6
Jul 07 02:34:28 master01 etcd[7471]: ready to serve client requests
Jul 07 02:34:28 master01 etcd[7471]: serving insecure client requests on [::]:4001, this is strongly discouraged!
Jul 07 02:34:28 master01 systemd[1]: Started etcd.
Jul 07 02:34:28 master01 etcd[7471]: ready to serve client requests
Jul 07 02:34:28 master01 etcd[7471]: serving insecure client requests on [::]:2379, this is strongly discouraged!
Jul 07 02:34:28 master01 etcd[7471]: set the initial cluster version to 3.3
Jul 07 02:34:28 master01 etcd[7471]: enabled capabilities for version 3.3
lines 1-19
And the health of the cluster itself:
etcdctl cluster-health member 61db137992290fc is healthy: got healthy result from http://10.73.71.27:2379 member b11e73358a31b109 is healthy: got healthy result from http://10.73.71.25:2379 member f67dd9aaa8a44ab9 is healthy: got healthy result from http://10.73.71.26:2379 cluster is healthy etcdctl member list 61db137992290fc: name=master03 peerURLs=http://10.73.71.27:2380 clientURLs=http://10.73.71.27:2379,http://10.73.71.27:4001 isLeader=false b11e73358a31b109: name=master01 peerURLs=http://10.73.71.25:2380 clientURLs=http://10.73.71.25:2379,http://10.73.71.25:4001 isLeader=false f67dd9aaa8a44ab9: name=master02 peerURLs=http://10.73.71.26:2380 clientURLs=http://10.73.71.26:2379,http://10.73.71.26:4001 isLeader=true
Stay tuned for a 2nd part of our guide in next article!