Despite the fact that most of the IT industry implements infrastructure solutions based on containers and cloud solutions, it is necessary to understand the limitations of these technologies. Traditionally, Docker, Linux Containers (LXC) and Rocket (rkt) are not truly isolated because they share the core of the parent operating system in their work. Yes, they are effective in terms of resources, but the total number of estimated attack vectors and potential losses from hacking are still large, especially in the case of a multi-rent cloud environment in which containers are located.
The root of our problem lies in the weak delimitation of containers at the moment when the host operating system creates a virtual user area for each of them. Yes, have been conducted research and development aimed at creating real “containers” with a full-fledged sandbox. And most of the resulting solutions lead to a restructuring of the boundaries between containers to enhance their isolation. In next articles, we will look at four unique projects from IBM, Google, Amazon, and OpenStack, respectively, which use different methods to achieve the same goal: creating reliable isolation. So, IBM Nabla deploys containers on top of Unikernel, Google gVisor creates a specialized guest kernel, Amazon Firecracker uses an extremely lightweight hypervisor for sandbox applications, and OpenStack places containers in a specialized virtual machine optimized for orchestration tools.
Overview of modern container technology
Containers are a modern way to package, share, and deploy an application. Unlike a monolithic application, in which all functions are packaged into one program, container applications or microservices are intended for targeted narrow use and specialize in only one task.
A container includes all the dependencies (for example, packages, libraries, and binaries) that an application needs to complete its specific task. As a result, containerized applications are platform independent and can run on any operating system, regardless of version or installed packages. This convenience saves developers from a huge work on adapting different versions of software for different platforms or clients. Although conceptually not entirely accurate, many people like to think of containers as “lightweight virtual machines.”
When a container is deployed on a host, the resources of each container, such as its file system, process, and network stack, are put into a virtually isolated environment that other containers cannot access. This architecture allows you to simultaneously run hundreds and thousands of containers in one cluster, and each application (or microservice) can then be easily scaled by replicating a large number of instances.
The container layout is based on two key “building blocks”: the Linux namespace and Linux control groups (cgroups).
The namespace creates a virtually isolated user space and provides the application with dedicated system resources such as the file system, network stack, process ID, and user ID. In this isolated user space, the application controls the root directory of the file system and can be run as root. This abstract space allows each application to work independently, without interfering with other applications located on the same host. Six namespaces are currently available: mount, inter-process communication (ipc), UNIX time-sharing system (uts), process id (pid), network and user. This list is proposed to be supplemented with two additional namespaces: time and syslog, but the Linux community has not yet decided on the final specifications.
Cgroups provide hardware resource limitation, prioritization, application monitoring and control. Examples of hardware resources that they can control include a processor, memory, device, and network. When combining the namespace and cgroups, we can safely run multiple applications on the same host, with each application in its own isolated environment – which is the fundamental property of the container.
The main difference between a virtual machine (VM) and a container is that the virtual machine is virtualization at the hardware level, and the container is virtualization at the operating system level. The VM hypervisor emulates the hardware environment for each machine, where the container runtime already in turn emulates the operating system for each object. Virtual machines share the physical hardware of the host, and containers share both the hardware and the OS core. Since containers generally share more resources with the host, their work with storage, memory, and CPU cycles is much more efficient than with a virtual machine. However, the drawback of this shared access is the problems in the plane of information security, since too much trust is established between the containers and the host. Picture below illustrates the architectural difference between a container and a virtual machine.
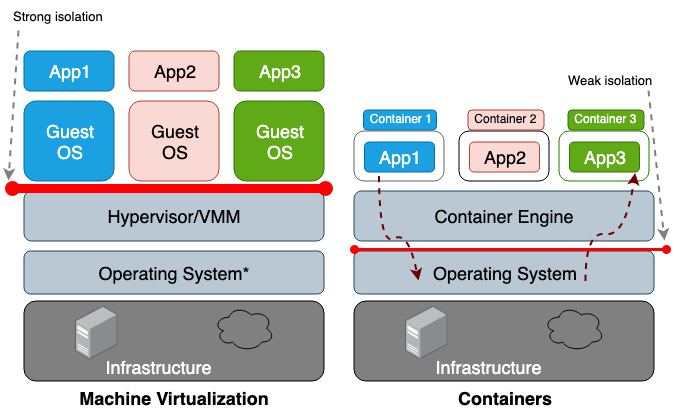
In general, isolation of virtualized equipment creates a much stronger security perimeter than just isolation of a namespace. The risk that an attacker successfully leaves an isolated process is much higher than the chance of successfully leaving the virtual machine. The reason for the higher risk of going beyond the limited container environment is the poor isolation created by the namespace and cgroups. Linux implements them by associating new property fields with each process. These fields in the / proc file system indicate to the host operating system whether one process can see another, or how much processor / memory resources a particular process can use. When viewing running processes and threads from the parent OS (for example, the top or ps command), the container process looks just like any other. Typically, traditional solutions, such as LXC or Docker, are not considered fully isolated because they use the same core within the same host. Therefore, it is not surprising that containers have a sufficient number of vulnerabilities. For example, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123, and CVE-2019-5736 could result in an attacker gaining access to data outside the container.
Most kernel exploits create a vector for a successful attack, because they usually result in privilege escalation and allow a compromised process to gain control outside its intended namespace. In addition to attack vectors in the context of software vulnerabilities, improper configuration can also play a role. For example, deploying images with excessive privileges (CAP_SYS_ADMIN, privileged access) or critical mount points (/var/run/docker.sock) may result as a leak. Given these potentially catastrophic consequences, you should understand the risk that you take when deploying the system in a multi-tenant space or when using containers to store sensitive data.
These problems motivate researchers to create stronger security perimeters. The idea is to create a real sandbox container that is as isolated from the main OS as possible. Most of these solutions include the development of a hybrid architecture that uses a strict distinction between the application and the virtual machine, and focuses on improving the efficiency of container solutions.
At the time of writing, there was not a single project that could be called mature enough to be accepted as a standard, but in the future, developers will undoubtedly accept some of these concepts as the main ones.
We will begin our review with Unikernel, the oldest highly specialized system that packs an application into one image using a minimal set of OS libraries. The Unikernel concept itself was foundational to many projects whose goal was to create safe, compact, and optimized images. After that, we will move on to consider IBM Nabla, a project to launch Unikernel applications, including containers. In addition, we have Google gVisor – a project for launching containers in the user kernel space. Next, we will switch to container solutions based on virtual machines – Amazon Firecracker and OpenStack Kata. To summarize this post by comparing all of the above solutions.