Over the past few years, we have seen an increased demand from customers for services related to the network component of the IT infrastructure. The need for the connectivity of IT systems, services, applications, monitoring and operational management of a business in almost any area are forcing companies today to pay increased attention to networks.
The range of requests – from providing network resiliency to creating and managing a client autonomous system with the acquisition of a block of IP addresses, configuring routing protocols and traffic management according to the policies of the organizations.
There is also a growing demand for complex solutions for building and maintaining network infrastructure, primarily from customers whose network infrastructure is being created from scratch or is outdated, requiring serious modification.
This trend coincided with the development and complication of our own network infrastructure. We expanded the geography of our presence in Europe by connecting to remote sites, which in turn required the improvement of the network infrastructure.
The company has launched a new service for customers, Network-as-a-Service: we take care of all the network tasks of our customers, allowing them to focus on their core business.
In the summer of 2020, the first large project in this field was completed, which I would like to talk about.
At the start
A large industrial complex contacted us for the modernization of the network part of the infrastructure at one of its enterprises. It was required to replace old equipment with new ones, including the network core.
The last modernization of the equipment at the enterprise took place about 10 years ago. The new management of the enterprise decided to improve connectivity, starting with infrastructure upgrades at the most basic, physical level.
The project was divided into two parts: an upgrade of the server park and network equipment. We were responsible for the second part.
The basic requirements for the work included minimizing the downtime of the production lines of the enterprise during the work (and in some areas the complete elimination of downtime). Any stop – direct financial loss of the client, which should not have happened under any circumstances. In connection with the operating mode of the facility 24x7x365, as well as taking into account the complete absence of periods of planned downtime in the practice of the enterprise, we were tasked, in fact, to perform open-heart surgery. This became the main distinguishing feature of the project.
How it was
The work was planned according to the principle of movement from the nodes of the network remote from the core to the closer ones, as well as from those less affecting the operation of production lines to those directly influencing this work.
For example, if you take a network node in a sales department, then an interruption in communication as a result of work in this department will not affect production in any way. At the same time, such an incident will help us, as a contractor, to check the correctness of the chosen approach to work on such nodes and, having adjusted the actions, work on the next stages of the project.
It is necessary not only to replace the nodes and wires in the network, but also to correctly configure all the components for the correct operation of the solution as a whole. It was the configurations that were checked in this way: starting work at a distance from the kernel, we kind of gave ourselves the “right to make a mistake,” without jeopardizing critical areas for the operation of the enterprise.
We have identified areas that do not affect the production process, as well as critical areas – workshops, loading and unloading block, warehouses, etc. At key areas, the client agreed on the permissible downtime for each node of the network separately: from 1 to 15 minutes … It was impossible to completely avoid the disconnection of individual network nodes, since the cable must be physically switched from the old equipment to the new one, and in the process of switching it is also necessary to untangle the “beard” of wires, which was formed during several years of operation without proper care (one of the consequences of outsourcing work on the installation of cable lines).
The work was divided into several stages.
Stage 1 – Audit. Preparation and approval of the approach to work planning and assessment of the readiness of the teams: the client, the contractor performing the installation, and our team.
Stage 2 – Development of a format for carrying out the work, with in-depth detailed analysis and planning. We chose a checklist format with an exact indication of the order and sequence of actions, up to the sequence of switching patch cords by ports.
Stage 3 – Carrying out work in cabinets that do not affect production. Estimation and adjustment of downtime for subsequent stages of work.
Stage 4 – Carrying out work in cabinets that directly affect production. Estimation and adjustment of downtime for the final stage of work.
Stage 5 – Work in the server room to switch the remaining equipment. Running on routing on a new kernel.
Stage 6 – Sequential switching of the system core from old network configurations to new ones for a smooth transition of the entire system complex (VLAN, routing, etc.). At this stage, we connected all users and transferred all services to new equipment, checked the correctness of the connection, made sure that none of the enterprise services stopped, ensured that in the event of any problems they would be connected directly to the kernel, which facilitated the elimination of possible troubleshooting and final setting.
Cabel “hairstyle”
The project was also challenging due to the difficult initial conditions.
First, it is a huge number of nodes and sections of the network, with an intricate topology and classification of wires according to their purpose. Such “beards” had to be taken out of the closets and painstakingly “combed”, figuring out which wire leads from where and where.
It looked somehow like this:

Somehow like that:

or like this:

Secondly, for each such task, it was necessary to prepare a file describing the process. “We take wire X from port 1 of the old equipment, we plug it into port 18 of the new equipment.” It sounds simple, but when you have 48 completely clogged ports in the initial data, and there is no idle option (we remember about 24x7x365), the only way out is to work in blocks. The more wires you can pull out of old equipment at a time, the faster they can be fixed and inserted into new network hardware, avoiding network disruptions and downtime.
Therefore, at the preparatory stage, we divided the network into blocks – each of them belonged to a specific VLAN. Each port (or a subset of them) on the old hardware is a VLAN in the new network topology. We have grouped them as follows: the first ports of the switch house the user networks, the middle – the production networks, and the last – the access points and uplinks.
This approach made it possible to pull out and make of the old equipment not 1 wire, but 10-15 wires at a time. This accelerated the workflow several times.
By the way, here’s what the wires look like in closets after “combing”:

or, for example, like this:

After the completion of the 2nd stage, we took a break to analyze errors and project dynamics. For example, minor flaws immediately came out due to inaccuracies in the network diagrams provided to us (an incorrect connector in the diagram is an incorrect purchased patch cord and the need to replace it).
The pause was necessary, since even a small failure in the process was unacceptable when working from server-side. If the goal was to ensure the downtime on the network section no more than 5 minutes, then it could not be exceeded. Any possible deviation from the schedule had to be agreed with the client.
However, preliminary planning and dividing the project into blocks made it possible to meet the planned downtime in all areas, and in most cases to do without it altogether.
Time challenge – project under COVID
However, there were some additional complications. Of course, the coronavirus was one of the obstacles.
The work was complicated by the fact that a pandemic began, and it was impossible for all specialists involved in the process to be present during the work at the client’s site. Only the installation staff were admitted to the site, and control was carried out through the room in Zoom – there was a network engineer from our side, I, as the project manager, a network engineer on the client’s side responsible for the production of work, and the team performing the installation work.
During the work, unaccounted for problems arose, and it was necessary to make adjustments on the fly. So it was possible to quickly prevent the influence of the human factor (errors in the scheme, errors in determining the status of the interface activity, etc.).
Although the remote work format seemed unusual at the beginning of the project, we quickly adapted to the new conditions and entered the final stage of work.
We ran a temporary network configuration to run two network cores in parallel, the old and the new one, to ensure a smooth transition. However, it turned out that one extra line from the configuration file of the new kernel was not removed, and the transition did not occur. This made us spend some time looking for the problem.
It turned out that the main traffic was transmitted correctly, and the control traffic did not reach the node through the new core. Thanks to the clear division of the project into stages, it was possible to quickly identify the section of the network where the difficulty arose, identify the problem and fix it.
As a result
Technical results of the project
First of all, a new core of the new enterprise network was created, for which we built physical / logical rings. This is done in such a way that each switch in the network has a “second shoulder”. In the old network, many switches were connected to the core via one route, one shoulder (uplink). If it was torn, the switch became completely inaccessible. And if several switches were connected through one uplink, then an accident put an entire department or production line at the enterprise out of action.
In a new network, even a rather serious network incident, under no scenario, will be able to “kill” the entire network or a significant part of it.
90% of all network equipment has been updated, media converters (signal propagation media converters) have been decommissioned, and the need for dedicated power lines to power equipment has been eliminated by connecting to PoE switches, where power is supplied via Ethernet wires.
Also, all optical connections in the server room and in the cabinets in the field are marked – at all key communication centers. This made it possible to prepare a topological diagram of equipment and connections in the network, reflecting its actual state today.
Network diagram
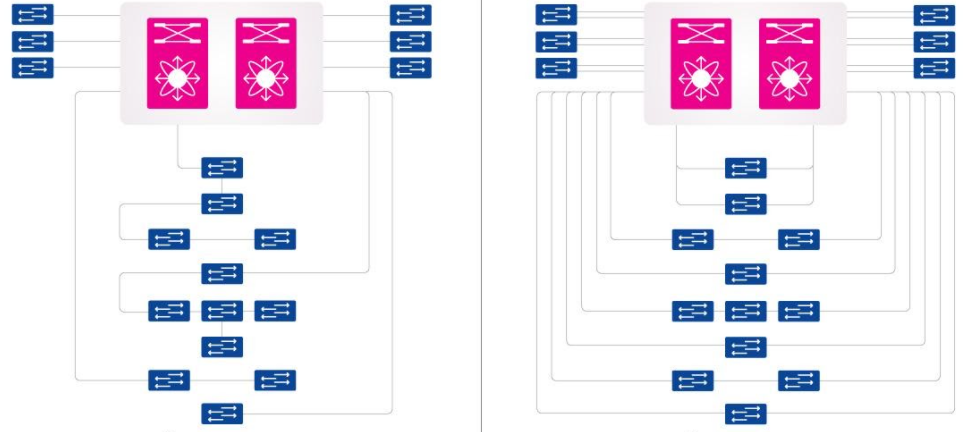
The most important result in technical terms: fairly large-scale infrastructure work was carried out quickly, without creating any interference in the operation of the enterprise and almost invisible to its staff.
Business results of the project
In my opinion, this project is interesting primarily not from the technical, but from the organizational side. The difficulty was primarily in planning and thinking through the steps to implement the project tasks.
The success of the project allows us to say that our initiative to develop a network direction within the portfolio of services is the right choice of the vector for the company’s development. A responsible approach to project management, a competent strategy, clear planning allowed us to perform the work at the proper level.
Confirmation of the quality of work – a request from the client to continue the provision of network modernization services at its other sites in Russia.