Immutable infrastructure is an approach to building infrastructure. Its idea is not new in the world, although not too widespread. We started using it when we realized that not everything can be run in Kubernetes, and we need virtual machines.
This is a virtual machine approach that should be treated as “packages” or containers. The virtual machine image, the application, and its environment are indivisible. Deploying a new version of the application involves creating a new image of a virtual machine, deploying a virtual machine from it and putting the machine into operation to replace the “old” virtual machines. In general, this is practically an attempt to make a container from a virtual machine.
Below we will look at the advantages and disadvantages of this approach, but first I would like to tell you one short story.
We in the company actively use the GCP cloud, so we do not administer the hardware on which the virtual machines are run. GCP has a powerful API and many SaaS products that make the Immutable approach possible. If you have KVM hosts, and you roll out virtual machines with a scriptwriter, then this solution is unlikely to suit you. But when using any cloud (Openstack, AWS, Azure, etc.), you can implement this approach. I will describe its use in conjunction with the full power of the cloud, where, for example, a virtual machine is created with a POST request, and the disk is increased on the fly.
Immutable benefits
This approach to organizing infrastructure carries almost all the same advantages that Docker and Kubernetes give, only for virtual machines:
Repeatable environment
Typically, an operating system of a certain version is installed on the server, the environment for the application is configured and the application itself is deployed. But if after some time you want to deploy exactly the same server with your application, then you will not be able to make “exactly the same”: some packages are outdated, security patches have been released for other packages, the kernel has also been updated. As a result, you end up with two “similar” servers. And this difference is often key and can lead to bugs and errors. With Immutable Infrastructure, you always have an image of a virtual machine that will start exactly and will repeat the real environment. Everything is already preinstalled in it: all system packages and libraries of the same version, and the application environment will not change over time. You can redeploy or scale the service years later, as long as you have an image.
Infrastructure as code
Immutable infrastructure is always described as code, because for each commit (release) we need to create a new image of the virtual machine, as well as run it through the CI / CD pipelines. This cannot be done manually.
Immutable environment
As with the Docker container, the virtual machine cannot be modified. Any configuration management tool or unattended upgrades will not come, which will install new versions of packages and break everything. These mechanisms are simply not there. They are not needed and even disabled on purpose, because everything that is needed for the application to function is already installed on the system. The environment is immutable over time and is always the same until a new version of the application is released.
Lack of drift configuration
It may happen that you have 100 servers on which you need to make a new update, and on several of them the layout has failed for some reason. Then your configuration gets ripped apart and you don’t have the same environment on all machines on your system. Or you have an unattended upgrade running, which periodically installs security updates, and somewhere it managed to install the package, but somewhere it didn’t. Immutable guarantees the immutability of virtual machines over time, as well as the fact that they have one identical version of all applications, dependencies and operating system.
Independence from external sources
During the setting up the environment, the application needs various dependencies that are pulled from external sources. If an external source is not available, the creation of new instances may fail. This won’t happen with Immutable. All dependencies are already installed in the image, which guarantees the performance of the application after the start. With this approach, we take the failure point to the stage of the image build, and not to the deployment stage, when something went wrong when upgrading to the production VM. After the image is assembled, we know for sure that the virtual machine is working, and it remains to deploy it as usual.
No legacy systems
With Immutable, there is no problem with “old” servers with high uptime, which are scary not only to update, but even to reboot. Any change is a new build of the image and a new virtual machine.
Easy scaling
There is always a slice in time of your application, you can bring up a new instance very quickly.
All the conses of the cloud
It is cheap and easy to create new resources in the cloud, request as much CPU and RAM as needed. In addition, you can integrate virtual machines with other GCP services: Load balancers, GCS for backups, Autoscaler, Cloud SQL, etc.
Development transformation
This approach to infrastructure and the realization that the infrastructure part is inseparable from the code and the application itself, that the minimum unit is a virtual machine, makes us change the approach to application development. You need to design your application based on the fact that it will be immutable. The application must be “aware” of its ephemerality and be ready to be replaced by a new version of itself. The deployment of such applications is also different, so you need to consider the nuances at the design stage.
Basic images
You can create images of virtual machines of the various OS with preinstalled software, which will be basic. Then they can be extended by installing specific applications and environments for them. All by analogy with Docker images.
Simple kickbacks
To roll back to the previous version, you just need to bring up the virtual machine with the previous image. As if you are launching a container.
Identical environments
You build a new virtual machine image and run it in the Dev environment for testing. If testing is successful, you run the SAME IMAGE (only with a different config for the provisioner) in the Prod environment.
But there are nuances
It never happens that everything is so rosy, and there are no pitfalls. In the case of Immutable, there are potential problems too. It all depends on the specific application, how it stores data, whether it can be scaled, whether it has clustering, how often it is deployed, how requests are processed, etc. So you should consider this list as possible problems when using Immutable infrastructure.
More complex deploy
Immutable means that every time you make any changes, you create a new image, based on which you start the virtual machine. After that, you may need to configure the application (so that it receives its variables, configs, joins the cluster, etc.). This all needs to be automated and can be quite difficult. The update pipeline and its logic can get sprawling.
Downtime on updates
If there is an application that runs on a virtual machine and uses some data stored locally, then laying out a new version of the application implies a number of processes: turning off the current virtual machine, disconnecting a disk from it, raising a new instance, connecting a disk to it. It is clear that this leads to downtime (to tell the truth, in this case, the break in the service, but simply shorter, would have been even if the Immutable approach had not been used). Bottlenecks: single instance and local storage. This can be solved through dynamic configuration systems, multiple instances (hot, cold standby or simultaneous operation), remote storage (but there will already be a possible downgrade of disk subsystem performance). It all depends on the specific case and application architecture. If these are Stateless workers, then this concept is suitable for them like no other. And we, for example, have an SLA on infrastructure services, within which we can sometimes do downtime for updating.
Lack of constant updates
Oddly enough, but Immutable has the downside of its own advantage – it is the lack of constant updates, security patches, etc., which in a normal system can be configured to automatically install. Nothing is updated in the image until you build and deploy the image you updated.
Above, I described this approach as an ideal case. We try to adhere to the Immutable ideology to the maximum, but how fully the idea can be realized depends on the application, its complexity, architecture, deployment features, etc. Sometimes it will not be possible to automate everything straightforwardly (or it will be expensive and laborious), so you always need to adhere to common sense. Don’t make Immutable for Immutable. First of all, you need to understand what benefits you will receive and whether they are enough. And are you ready for the disadvantages.
Push and Pull models
When designing, you need to consider which model your application will fit. There are two main ways:
Push
This model does not imply that the application can automatically scale, and, accordingly, the number of virtual machines is strictly constant over time. This means that a new machine is launched on a commit – a new image is built, a new virtual machine is created, CI / CD rolls the necessary configuration into it, the application is launched. That is, the configuration takes place outside – it is pushed into the virtual machine.
Pull
With this approach, autoscaling can work, and virtual machines will be in an instance group (well, or use a similar mechanism). This means that the creation of a new virtual machine will occur automatically, and not at the will of the operator or the CI process. The newly created machine must have everything necessary for the configuration itself. That is, the configuration comes from the inside – it is pulled by the virtual machine itself (into itself).
Depending on the model, you need to approach the design of the CI / CD pipeline and the deployment process differently.
When working with immutable infrastructure, these tools help us:
- Packer is a program from Hashicorp that allows you to create images of virtual machines, based on different cloud providers. Packer takes the specified base image, creates a virtual machine from it in the required cloud provider, rolls the configuration into it using any of the many providers, and at the end creates an installation image from its disk that can be used in the selected cloud.
- Terraform is another utility from Hashicorp that probably needs no introduction anymore. It allows you to describe the necessary infrastructure resources of the required cloud provider and, using this manifest, brings the cloud configuration to the one described in the config.
- Ansible is a tool that just about everyone is familiar with. We need it in order to provision the image and the created virtual machine – to configure the environment.
- Gitlab CI – we use Gitlab, so we write all automation on it.
- GCP is actually a cloud that makes running a virtual machine easy and simple, and also allows you to create many other resources.
Immutable Images
The VM image is the main artifact of the deployment. We have our own base images that are built on the basis of Google images specially tailored for working in their cloud, images of applications with some pre-installed but not configured software (nginx, mysql, mongodb, etc.), and product images … The latter contains everything necessary for the operation of a specific product or its component (this can be an image with a configured database, web server, backend). As you can understand, each image in the hierarchy is based on some parent and extends it. For image configuration (environment preparation) we use Ansible – a great tool for delivering one-shot configuration.
If you are developing the concept of virtual machine images, it is important to come up with and implement an image naming convention as early as possible. The name of the image should clearly and unambiguously identify the OS on the basis of which it is built, and its main function (software, its version), for which it was built. Then it will be much easier and more convenient to work with them in the future.
Image Family
An image in GCP has a name, labels, status, and also belonging to some Image Family.
Image Family is a convenient mechanism that unites all versions of one image under one “family”. This makes it easier to use the base images – if you don’t need to know exactly which version of the image you are using, its name, which includes the date, etc., you just specify the image family that you want to build from, and that’s it. It is analogous to the latest tag in docker.
However, if using the Image Family when building an image is quite justified, then when deploying you must use the Image Name and indicate the specific image that you want to deploy (just built). Like the latest in docker, using family can lead to versions drifting or unexpected changes in production.
Briefly, the principle of working with Image Family looks like this:
You have image-v1 – this is the most recent version of your application image. my-image-family points to the given image
gcloud compute images create image-v1 \ --source-disk disk-1 \ --source-disk-zone us-central1-f \ --family my-image-family gcloud compute images describe-from-family my-image-family family: my-image-family id: '50116072863057736' kind: compute # image name: image-v1
You create a new image, image-v2, and now my-image-family points to it.
gcloud compute images create image-v2 \ --source-disk disk-2 \ --source-disk-zone us-central1-f \ --family my-image-family gcloud compute images describe-from-family my-image-family family: my-image-family id: '50116072863057756' kind: compute # image name: image-v2
For some reason, you need to rollback to the previous version and now my-image-family points to image-v1 again:
gcloud compute images deprecate image-v2 \ --state DEPRECATED \ --replacement image-v1 gcloud compute images describe-from-family my-image-family family: my-image-family id: '50116072863057736' kind: compute # image name: image-v1
Updating and Rotating Base Images
Images have their own life cycle. After all, if we updated the image, we did it for a reason? Most likely, security updates, new versions of applications with new features, etc. were installed. Users must somehow be told that their image is outdated and there is a newer image.
The virtual machine images in GCP have a current state:
- READY – the image is ready to use
- DEPRECATED – the image is deprecated. Such images are not displayed in the web console by default, but are available for gcloud and terraform. If they are used, a warning is issued.
- OBSOLETE – the image in this status is no longer available for use.
- DELETED – The image is marked as deleted, but still physically exists.
- REALLY_DELETED – there is no such status in reality, but after a while, as the image was marked DELETED, it will be deleted for real.
Using these statuses, we have created a rotation process for images. The picture below shows the life cycle of an image and its main stages.
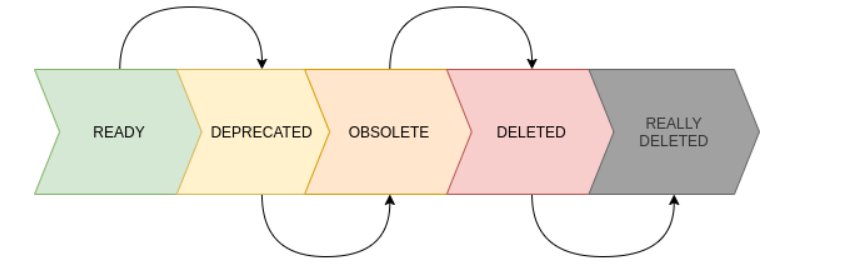
For base images, we do auto-update. Once a day, an automatic check is made for updates to the packages included in the image. If updates are found, a new version of the image is built and the image-family pointer is shifted to it. After that, all images related to this image-family are rotated.
To automate the life cycle, we wrote the image-rotator script, which we will publish in the public domain in the near future.
- The necessary variables are passed to the script, the main of which is –image-family. This is how it understands what it needs to work with.
- The script finds all images belonging to this Image Family, and then works with all these images EXCEPT the last actual image that Image Family is pointing to at the moment
- Further, among these images, he does the following:
All READY images are made DEPRECATED and given a date when they should become OBSOLETE
All DEPRECATED images that have obsolete date less than the current date are transferred to the OBSOLETE state and set the date when the image should become DELETED
All OBSOLETE images are processed by analogy with DEPRECATED
It’s the same with DELETED. If the DELETED image has the date of deletion, the script deletes the image permanently
Pipeline diagram
So, now that we have figured out the main points, we can consider the general deployment process.
The figure below shows schematically this process.
We assume that first, we deploy the application to the Dev environment from the Master branch (the name of the branch is not important here), where it is tested. After that, we will deploy the same image to the Prod environment from another branch – stable, by synchronizing the two branches via Merge Request.
This pipeline is schematic and can be complicated to achieve specific goals or complete automation. For example, in our pipelines, in addition to what is shown in the diagram is automated:
- Integration with Hashicorp Vault to get secrets
- Using snapshots of Prod instance data disks to create a Dev environment
- Using the latest CloudSQL backup (note: database as a service from Google (MySQL, PostgreSQL)) Prod instance to create a database in Dev environment
- Removing the Dev environment at the end of testing (it’s the same cloud, we don’t want to spend extra money)
Next, Terraform creates a virtual machine with an application in the Dev environment, creates a disk with fresh data from the image made in step 1. So we get fresh independent data on which we will test the new virtual machine. As a bonus, we check Prod’s backups “by accident” 🙂
Conclusion
This is the end of the theory. And unfortunately (or fortunately for those who do not like a lot of letters), I finish my post with the most interesting, since the article has already turned out to be quite voluminous, and it will no longer accommodate a real example of a service deployed using this concept. Write in the comments if the article turned out to be interesting / useful, and you want to see how it is done in practice: with the code, real CI / CD and explanations. I will be grateful for your feedback.
Immutable Infrastructure is an approach that has its pros and cons. An approach that may not work for every service or application. And I repeat, you must use it, understanding and accepting all its pros and cons. And of course, let common sense always prevail. You can always take a part of it and only use it if it gives you an advantage.
Now we in the team are working on improving the concept and our implementation, because after some time using it in the form in which it is described here, we realized that we have something to work on, and we have ideas on how to do everything better. And when everything works out, we will write another article in which we will share our best practices.