Caching s3 in nginx
S3-compatible cloud storage has long been included in the list of technologies used by many projects. If you need reliable image storage for your site or for neural network data, Amazon S3 is a great choice. Reliability of storage and high data availability is captivating.
However, sometimes to save money – because usually the payment for S3 is for requests and for traffic – a good solution is to install a caching proxy server for the storage. This method will reduce costs when it comes, for example, to user avatars, of which there are many on each page.
It would seem that it is easier than taking nginx and setting up proxywith caching, revalidation, background updating and other blackjack? However, there are some nuances …
An approximate configuration of such proxy with caching looked like this:
proxy_cache_key $uri;
proxy_cache_methods GET HEAD;
proxy_cache_lock on;
proxy_cache_revalidate on;
proxy_cache_background_update on;
proxy_cache_use_stale updating error timeout invalid_header http_500 http_502 http_503 http_504;
proxy_cache_valid 200 1h;
location ~ ^/(?<bucket>avatars|images)/(?<filename>.+)$ {
set $upstream $bucket.s3.amazonaws.com;
proxy_pass http://$upstream/$filename;
proxy_set_header Host $upstream;
proxy_cache aws;
proxy_cache_valid 200 1h;
proxy_cache_valid 404 60s;
}
And in general, it worked: pictures were displayed, everything was fine with the cache … however, problems surfaced with AWS S3 clients. In particular, the client from aws-sdk-php stopped working. The analysis of nginx logs showed that upstream returned 403 code for HEAD requests, and the response contained a specific error: SignatureDoesNotMatch. When we saw that nginx makes a GET request to upstream, everything start to be clear.
The fact is that the S3 client signs each request, and the server checks this signature. In the case of simple proxy process, everything works fine: the request reaches the server unchanged. However, when caching is enabled, nginx begins to optimize its work with the backend and replaces the HEAD requests with GET. The logic is simple: it is better to get and save the whole object, and then all HEAD requests from the cache too. However, in our case, the request cannot be modified, because it is signed.
There are essentially two solutions:
- Do not drive S3 clients through proxies;
- if it’s “necessary”, turn off the proxy_cache_convert_head option and add $ request_method to the cache key. In this case, nginx sends HEAD requests “as is” and caches responses to them separately.
DDoS and Google User Content
Sunday evening did was going without problems until – suddenly! – the queue of cache invalidation on edge servers has not grown, which gives traffic to real users. This is a very strange symptom: after all, the cache is implemented in memory and is not tied to hard drives. Flushing the cache in the architecture used is a cheap operation, because this error can only appear in the case of a really high load. This was confirmed by the fact that the same servers began to notify of the appearance of 500 errors (red line spikes in the graph below).
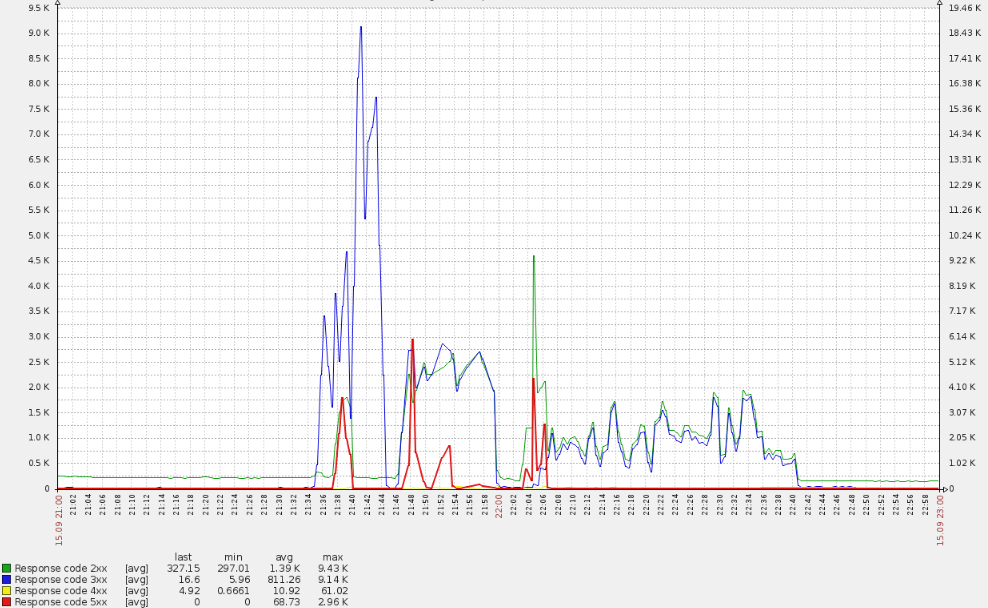
Such a sharp surge led to CPU overruns:
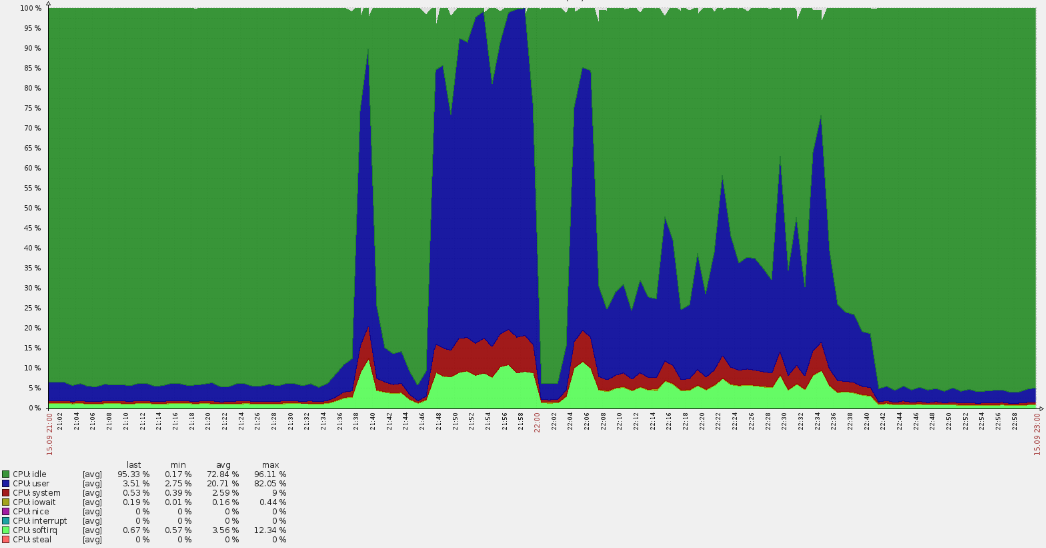
A quick analysis showed that the requests didn’t come to the main domains, but from the logs it became clear that they fall into default vhost. Along the way, it turned out that many American users came to the Russian resource. Such circumstances always immediately raise questions.
Having collected data from the nginx logs, we revealed that we are dealing with a certain botnet:
35.222.30.127 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?ITPDH=XHJI" HTTP/1.1 301 178 "http://example.ru/ORQHYGJES" "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?ITPDH=XHJI" "redirect=http://www.example.ru/?ITPDH=XHJI" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?REVQSD=VQPYFLAJZ" HTTP/1.1 301 178 "http://www.usatoday.com/search/results?q=MLAJSBZAK" "Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?REVQSD=VQPYFLAJZ" "redirect=http://www.example.ru/?REVQSD=VQPYFLAJZ" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?MPYGEXB=OMJ" HTTP/1.1 301 178 "http://engadget.search.aol.com/search?q=MIWTYEDX" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?MPYGEXB=OMJ" "redirect=http://www.example.ru/?MPYGEXB=OMJ" ancient=1 cipher=- "LM=-;EXP=-;CC=-"
A clear pattern is visible in the logs:
- true user-agent;
- a request to the root URL with a random GET argument to avoid getting into the cache;
- referer indicates that the request came from a search engine.
We collect the addresses and verify their affiliation – they all belong to googleusercontent.com, with two subnets (107.178.192.0/18 and 34.64.0.0/10). These subnets contain GCE virtual machines and various services, such as page translation.
Fortunately, the attack didn’t last so long (about an hour) and gradually decreased. It seems that the protective algorithms inside Google have worked, so the problem was solved “by itself.”
This attack was not destructive, but raised useful questions for the future:
- Why didn’t anti-ddos work? An external service is used, to which we sent a corresponding request. However, there were a lot of addresses …
- How to protect yourself from this in the future? In our case, even options for closing access on a geographical basis are possible.