Google gVisor
Google gVisor is a sandbox technology, which uses the Google Cloud Platform Application Engine (GCP), cloud features, and CloudML. At some point, Google realized the risk of running untrusted applications in the public cloud infrastructure and the inefficiency of sandbox applications, which are using virtual machines. As a result, a user-space kernel was developed for an isolated environment of such unreliable applications. gVisor puts these applications in the sandbox, intercepting all system calls from them to the host kernel and processing them in the user environment using the gVisor Sentry kernel. Actually, it functions as a combination of a guest core and a hypervisor. Picture below shows the gVisor architecture.
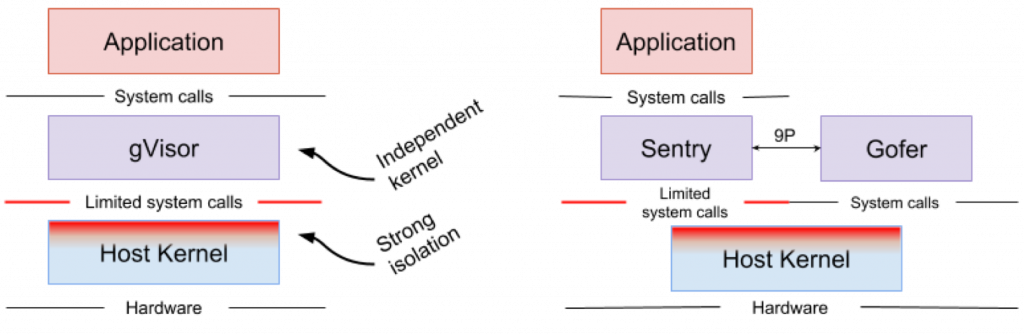
gVisor creates a strong security perimeter between the application and its host. It limits the system calls that applications can use in user space. Without relying on virtualization, gVisor works as a host process that interacts between a stand-alone application and a host. Sentry supports most Linux system calls and core kernel features such as signal delivery, memory management, network stack, and stream model. Sentry implements over 70% of the 319 Linux system calls to support sandboxed applications. However, Sentry uses less than 20 Linux system calls to interact with the host kernel. gVisor and Nabla have a very similar strategy: protecting the host OS and both of these solutions use less than 10% of Linux system calls to interact with the kernel. But you need to understand that gVisor creates a multi-purpose kernel, and, for example, Nabla relies on unique kernels. At the same time, both solutions launch a specialized guest kernel in user space to support isolated applications trusted by them.
Someone may wonder why gVisor needs its own kernel when the Linux kernel is already open source and easily accessible. So, the gVisor kernel written in Golang is more secure than the Linux kernel written in C. All because of the powerful type safety and memory management features in Golang. Another important point regarding gVisor is its tight integration with Docker, Kubernetes, and the OCI standard. Most Docker images can simply be retrieved and run using gVisor by changing the runtime to gVisor runsc. In the case of Kubernetes, instead of a sandbox, for each individual container in gVisor, you can run an entire sandbox module.
For now gVisor still has some limitations. When gVisor intercepts and processes the system call created by the application from the sandbox, costs always arise, so it is not suitable for heavy applications. (Note that Nabla doesn’t have such problems because unikernel applications do not make system calls. Nabla uses seven system calls only to handle hypercall). GVisor doesn’t have direct hardware access (passthrough), therefore applications that require it, for example, to the GPU, cannot work in it. Finally, since gVisor only supports 70% of Linux system calls, applications that use calls that are not on the support list cannot run on gVisor.
Amazon firecracker
Amazon Firecracker is the technology used today in AWS Lambda and AWS Fargate. It is a hypervisor that creates “lightweight virtual machines” (MicroVMs) specifically for multi-tenant containers and serverless operating models. Before Firecracker, the Lambda and Fargate functions for each client worked inside dedicated EC2 virtual machines to provide reliable isolation. Although virtual machines provide sufficient isolation for containers in the public cloud, using both general-purpose virtual machines and virtual machines for applications with isolated environments is not very efficient in terms of resource consumption. Firecracker solves both security and performance issues by being designed specifically for cloud applications. The Firecracker Hypervisor provides each guest virtual machine with the minimum OS functionality and emulated devices to enhance both security and performance. Users can easily create virtual machine images using the Linux kernel binary and the ext4 file system image. Amazon began developing Firecracker in 2017, and in 2018 opened the project source code to the community.
Like the unikernel concept, Firecracker provides only a small subset of functions to ensure container operations. Compared to traditional virtual machines, micro-VMs have far fewer potential vulnerabilities, as well as memory consumption and startup time. Practice shows that Firecracker’s micro-VM consumes about 5 MB of memory and loads in ~ 125 ms when working on a host with a configuration of 2 CPU + 256 GB RAM. Picture below shows the Firecracker architecture and its security perimeter.
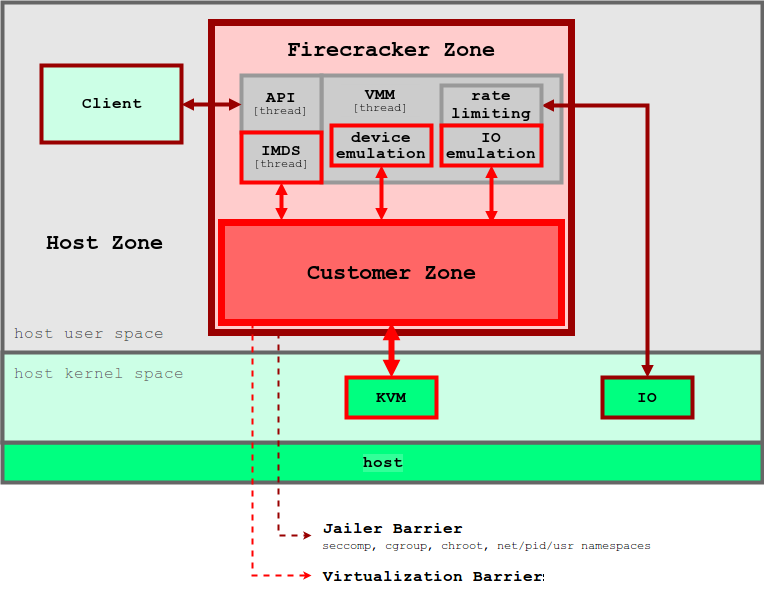
Firecracker is based on KVM, and each instance runs as a process in user space. Each Firecracker process is blocked by the policies of seccomp, cgroups and namespaces, so system calls, hardware resources, the file system and network actions for it are strictly limited. Within each Firecracker process there are several threads. So, the API stream enables management between clients on the host and microVM. The hypervisor thread provides a minimal set of virtIO devices (network and block). Firecracker provides only four emulated devices for each microVM: virtio-block, virtio-net, serial console, and 1-button keyboard controller designed only to stop microVM. For the same security purposes, virtual machines don’t have a mechanism for exchanging files with the host. Host data, such as container images, interact with microVM through File Block Devices, and network interfaces are supported through a network bridge. All outgoing packets are copied to a dedicated device, and their speed is limited by the cgroups policy. All these precautions and information security ensure that the possibility of one application affecting others is minimized.
Firecracker has not yet fully completed the integration process with Docker and Kubernetes. Firecracker doesn’t support end-to-end hardware connectivity, so applications that require a graphics processor or any accelerator to access devices are not compatible with it. It also has limited file sharing capabilities between virtual machines and a primitive network model. However, since the project is being developed by a large community, it should soon be brought to the OCI standard and start supporting more applications.
Openstack kata
Because of the security problems of traditional containers, in 2015 Intel introduced a proprietary technology based on Clear Containers virtual machines. Clear Containers are based on Intel VT virtualization hardware technology and the highly modified QEMU-KVM qemu-lite hypervisor. At the end of 2017, the Clear Containers project joined Hyper RunV, a hypervisor-based OCI, and began developing the Kata project. Inheriting all the properties of Clear Containers, Kata now supports a wider range of infrastructures and specifications.
Kata is fully integrated with OCI, the container runtime interface (CRI), and the network interface (CNI). It supports various types of network models (for example, passthrough, MacVTap, bridge, tc mirroring) and custom guest kernels, so that all applications that require special network models or kernel versions can work on it. Picture below shows how containers inside Kata virtual machines interact with existing orchestration platforms.
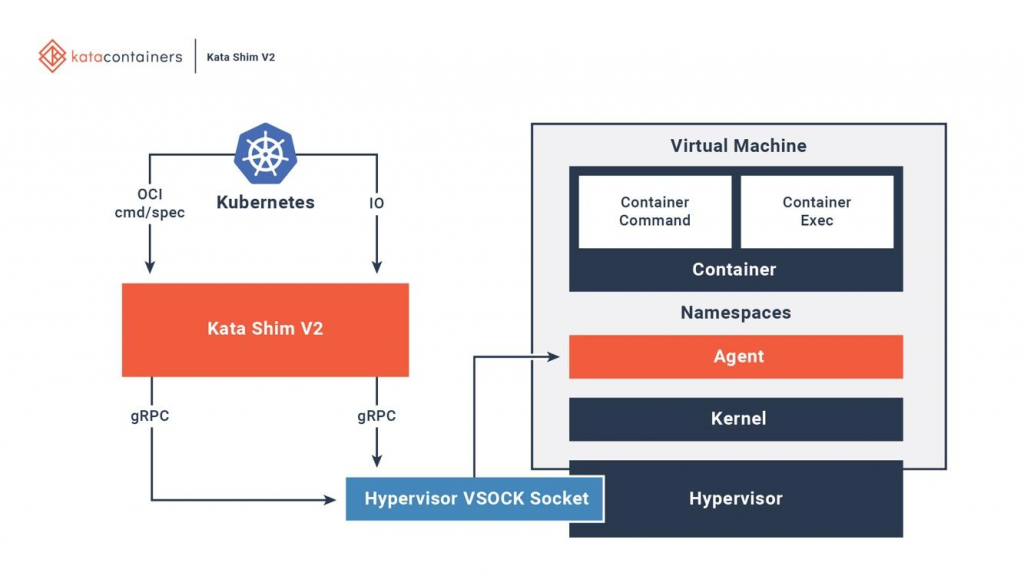
The Kata host has a startup and configuration environment. For each container in the Kata virtual machine, the host has a corresponding Kata Shim, which receives API requests from clients (for example, docker or kubectl) and routes requests to the agent inside the virtual machine through VSock. Additionally, Kata optimizes download times. NEMU is a lightweight version of QEMU from which ~ 80% of devices and packages have been removed. VM-Templating creates a clone of a running Kata VM instance and shares it with other just created VMs. This significantly reduces the loading time and memory consumption of the guest machine, but can lead to vulnerabilities for side-channel attacks, for example, according to CVE-2015-2877. The ability to connect on spot allows the VM to boot with a minimum amount of resources (for example, CPU, memory, virtio block), and later add the missing on demand.
Kata and Firecracker containers are virtual machine sandbox technology designed for cloud applications. They have one goal, but different approaches. Firecracker is a specialized hypervisor that creates a secure virtualization environment for guest OSs, while Kata containers are lightweight virtual machines that are well optimized for their tasks. There have been attempts to launch Kata containers on Firecracker. Although this idea is still in the experimental stage, it could potentially combine the best features of the two projects.
Conclusion
We examined several solutions whose purpose is to help with the problem of poor isolation of modern container technologies.
IBM Nabla is a unikernel-based solution that packs applications into a dedicated virtual machine.
Google gVisor is a combination of the specialized core of the hypervisor and the guest OS that creates a secure interface between applications and their host.
Amazon Firecracker is a specialized hypervisor that provides each guest OS with a minimal set of hardware and nuclear resources.
OpenStack Kata is a highly optimized virtual machine with a built-in container engine that can run on a variety of hypervisors.
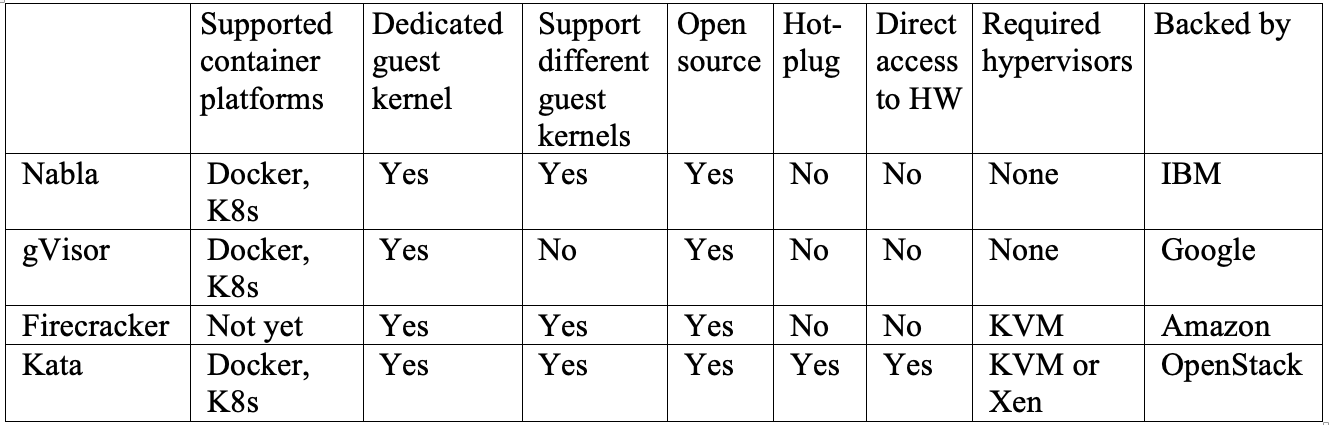
It is difficult to say which of these solutions works best, since they all have their pros and cons. The table at the end of the article provides a parallel comparison of some important functions of all four projects. Nabla would be the best choice if you have applications running on unikernel systems such as MirageOS or IncludeOS. gVisor now integrates best with Docker and Kubernetes, but due to incomplete coverage of system calls, some applications are not compatible with it. Firecracker supports custom guest OS images and is a good choice if your applications should run in a configured virtual machine. Kata containers are fully compliant with the OCI standard and can run on either KVM or the Xen hypervisor. This can simplify the deployment of microservices on hybrid platforms.
It may take some time for one of the solutions to become the standard, but it’s good now that most of the large cloud providers have begun to look for solutions to existing problems.