For clarity, let’s compare self-hosted and managed solutions in two aspects:
- Labor costs and competence of specialists.
- Hardware and infrastructure.
Specialists
To maintain a Kubernetes cluster, whether it is your own or rented, you will need people with certain competencies.
self-hosted
infrastructure team. People who will deal with hardware, network and data center. They are in the company when you keep your own servers or even an entire data center. But most often now companies rent the servers themselves, and the hoster is responsible for the hardware. In this case, you only need to monitor servers and order new ones if necessary. A separate command is not needed for this – ordinary administrators can handle it.
Kubernetes administrators. Actually, those who work with the cluster: deploy it, configure it, maintain it, expand it, and monitor the load. It is they who can be entrusted with the infrastructure that rests on rented servers.
They will also integrate the cluster with external services, such as storage systems or load balancers. And make sure that the centralized collection of logs, backup systems, monitoring systems, CNI, CSI, DNS and the control plane work.
Automation team. These guys are engaged in DevOps – they help developers deploy applications to Kubernetes, set up CI / CD, together with the k8s admin team, they do not allow deployment of manifests that can lead to problems. For example, deployments in which the number of pod replicas is equal to one and which are not at all fault-tolerant.
Managed
Cloud team. The hoster has a team of infrastructural workers – it is they who ensure the performance of the hardware. But the company needs people who understand how the cloud works and how to handle it. You can’t do without them, even if most clouds say that they are simple and friendly with users. This will help to avoid situations when you receive a bill for tens of thousands of dollars at the end of the month. for capacities that you accidentally ordered and did not use.
Kubernetes administrators. Yes, you don’t need to install Kubernetes, configure it, and scale it. But the tasks of maintaining monitoring, collecting logs, validating manifests and stopping incorrect deployments remain. There will be fewer of them than on our own servers, but the automation team will not cope with them – separate people will be needed.
Automation team. You need DevOps anyway, and a cloud provider won’t provide it.
If you are not a small startup that is working on MVP, but a normal production, then the difference will be only in the areas of knowledge. The teams will need plus or minus the same, but in the first case, hardware administrators will be needed, and in the second, cloud engineers. What will be more expensive depends on the market situation.
Hardware and infrastructure
self-hosted
First of all, we need ordinary hardware servers with Linux, combined into a local area. But there is a problem – the power of one such server is excessive for a Kubernetes node. On the default node, we run 110 pods, in the pod 2 (rarely 3-4) containers, each pod is a separate microservice. As a result, we have only 110 microservices on a 12-core 128-gigabyte server that cannot utilize it 100%.
As a solution, one hardware server is usually split into several KVM virtual machines. As a result, there are nodes where some heavy applications like Legacy Java run – they have been given a whole server. And for small ones, one node per KVM is allocated, part of a large server.
Such a system can be created on your own hardware or in the cloud. The cloud here is not managed Kubernetes, but only servers. Let’s see what are the pros and cons of each solution.
On your hardware
Pros:
- Local drives are much faster than any network storage.
- Renting (and even buying) servers will cost less than a managed solution in the cloud.
Minuses:
- Hardware needs to be serviced and repaired sometimes: to replace cooling systems, patch cords and disks. This requires people and a separate budget for spare parts.
- To add a new node, you need to order a server, bring it in, place it in a rack, and make initial settings.
- If your application needs persistent volumes, you will need separate storage systems that can be attached to any node.
- It is necessary to raise a fault-tolerant balancer with reservation of IP addresses.
In the cloud
Pros:
- Most cloud providers now have a local SSD service. When everything is launched not on an external network drive, but directly on a disk inside the hypervisor. So the possibility of migrating a virtual machine from one hypervisor to another is lost, but speed appears, as on hardware servers.
- Cloud drives can be used as a data storage system, everything is set up and working.
- To add new nodes, you can cut a new virtual machine at any time, you do not need to buy and configure anything.
- A cloud load balancer that takes care of redundancy.
Minuses:
- You still have to configure the integration of our Kubernetes cluster with the cloud yourself: read the documentation, create users with the necessary rights in the cloud, register user keys in CSI drivers, launch and configure the Cloud controller so that you can create balancers.
In my opinion, virtual machines in the cloud look a little better than hardware servers. In terms of the speed of local disks, we have parity, and in terms of setting up and working with storage systems, the cloud definitely wins – you don’t need to implement anything yourself.
Managed
Here we have a cluster running a hoster. And there are three options:
- It’s normal when the control plane works outside the cloud, and we don’t see it. The hoster does everything: configures, maintains, monitors performance.
- It’s strange when the entire managed solution consists of a button in the web interface, where we set the number and size of nodes in order to get a cluster in 10 minutes. And the control plane is running on exactly the same virtual machine, and we ourselves must manage it.
- Average. For example, when the control plane is in the cloud, but there are rudiments of automation. Or when the control plane is not available to us at all, but there is a minimum of automation. It all depends on the host.
I’ll give you an example. Two years ago, we looked at managed solutions from Selectel. They had an option with a control plane in the cloud. In fact, it was the automation of the launch of Kubernetes with the integration of storage systems, but the control plane was launched in the same cloud, and no one controlled it. And recently I studied the Selectel proposal again and saw that they completely redesigned the proposed managed solution to a normal version. The control plane is hidden from the user, and the watchdog monitors the worker nodes, and if the worker node stops responding, it is killed and a new one is automatically raised.
Let’s move on to the features of managed solutions and the differences from the Kubernetes cluster that we raised with our own hands.
Let’s talk about the pros first:
- Easy installation. We say: “I want 2 groups of nodes. One on spot servers, the second with autoscaling, 4 cores, 16 memory. Turn on my PSP right away or some other add-ons. settings”. All this is enough to stick with the mouse in the graphical interface or set in Terraform – and the cluster appears.
- Cloud drives as storage. You can attach storage systems to nodes as a persistent volume. True, there are limitations – depending on the cloud, this can be no more than 16 or 64 disks per node.
- Fast addition of nodes. The load has grown – you can order a dozen more virtual machines. Moreover, it is easy to set up the autoscaler to do this automatically.
- Cloud balancer. We simply say: “We want to receive a request from the Internet. Cloud, build a balancer and swear it will be fault tolerant.” And you don’t need to think about using Cloudflare or somehow transfer IP between your virtual machines.
- Cloud integration is ready. There are all Storage class, you can quickly connect the desired disk to any node.
- Auto recovery. Not just nodes that were killed, but system stuff that can’t be hidden in the control plane. For example, these are the Calico settings: log level, debug, and so on. The auto-recovery system can push original manifests to the cluster once a minute so as not to accidentally break CNI, CSI, kube proxy and other components that you have access to.
Now let’s move on to the cons:
- Technical support is designed for the mass user. The first line often doesn’t have much technical background and can only say, “Please check if you’re deploying correctly.” You also need to convince them that the problem is not with you, but in the cloud, and wait until you get to the second line. Plus, sometimes you have to wait several weeks for a response to tickets.
- Average settings. There is no fine tuning for your load profile, which is why you have to overpay for power.
- Explicit and implicit restrictions. Often there are resource quotas, but they can be asked to increase. And there are “secrets” – for example, only 50 thousand network connections per virtual machine can be available. Most of this is enough, but Kubernetes has a lot of DNS requests over UDP, and you can easily burn out these 50 thousand connections. This is easy to fix with NodeLocal DNS, but be aware that this can happen. And information about 50 thousand connections is indicated in small print in the far corner of the documentation. And this is just an example – there can be many such implicit restrictions.
- Complex cloud infrastructure. The cloud is supported by people, and they are different. Some changes or problems may come from above, and while they are being solved, your application will suffer. And you can’t influence it.
- Simplified auto-recovery. We cannot fine-tune things that are not available to us. For example, there was a situation with Calico logs. We had a cluster of developers who rolled out new microservices every five minutes. As a result, dozens of new pods appeared, and the Calico pods loaded the processors on the nodes quite heavily, carefully recording all their actions in the logs, with debugging turned on. And then it was still transferred to Elasticsearch. It turned out that Elastic swelled up, kept unnecessary debug logs and wasted CPU time and disks on useless work. And technical support answered that there was no way to fix this – only turn off auto-recovery completely.
What is the result
Managed is a great solution for low-load projects. Creating a cloud to test the concept is ideal, because you can not bother with the technical infrastructure and go headlong into deployment tasks.
Loaded production is another story. In the case of Managed, you need a very fast response from technical support, and many providers charge extra for this. This is already somewhat reminiscent of outsourcing – you hire a team from the provider, and it solves problems. But in the cloud, this team can be involved in the problems of other users, and it may be wiser to take it not from the provider, but on the side. And decide for yourself whether you are ready for the disadvantages of a managed cloud or still deploy your own Kubernetes yourself for finer tuning.
What to look for in managed solutions: obvious but important
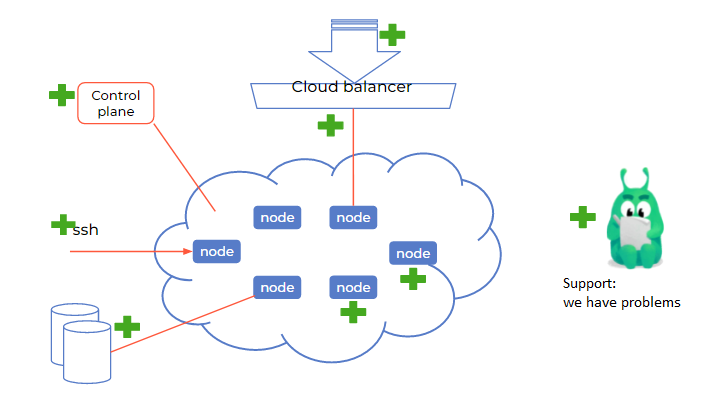
Mandatory
Control plane managed by the host. It is the hoster that should be responsible for its performance and have automatic recovery systems. If you see the control plane inside your cloud, you can immediately change the provider.
Integration with the cloud as with storage. This is almost everywhere, but it’s better to check that you can connect cloud disks as a persistent volume to your cluster.
Working cloud balancer. First, it must be. Secondly, load balancers should be created for services of the load balancer type. It is better if they can be controlled, for example, by setting an external IP through an annotation. So that if a load balancer service is accidentally disabled, then create it with the same IP address and not change addresses in your DNS zones.
Access to nodes via SSH. Typically, managed solutions focus on the operation of the control plane. Therefore, you need direct access to nodes in order not just to kill them and create them again, but to solve problems with incorrect limits and eaten memory. Without access, you can simply see in the web interface that the node is “red” and something is wrong with it, but you will not be able to fix something.
Load resistance. To check this, you can create two or three dozen namespaces, deploy your application on each in parallel and simulate external traffic. This way you will understand whether the cluster will cope with peak loads and find out where to expect problems from – from your application or from a managed cluster.
Support work. During all these tests, you will probably need technical support. This is a great opportunity to check how it works and whether it answers correctly. For example, they may start asking you how exactly you use the balancer, what is its IP, what is the ID of your clusters. And they can see everything for themselves, which, of course, is better.
Cluster autoscaling operation. To test it, fill the cluster with pods with requests so that there is no free space left. And see if new nodes appear. Then remove unnecessary pods and see if the added nodes are removed. Because sometimes autoscaling works only in one direction – it creates, but does not delete. And after the load drops, unnecessary nodes continue to pull money from you.
Not required but useful
Possibility of monitoring through the web interface. So that you can watch the loading of the kernel and memory, and ideally, disks. View manifests, especially if you are not very good at using kubectl. In general, visually see the state of clusters, nodes and control plane.
Own proxy. Proxy registry for Docker hub is a very handy thing. Often, managed solutions from all 20 nodes go outside through 1 IP address. And getting 100 pools in six hours is very easy. Proxy will fix this situation.
Fresh versions of clusters. Somehow I saw a solution whose latest cluster was version 1.19. And there is already 1.23, 1.19 is even taken out of service.
Runtime interface container. It should be containerd or CRI-O – no Docker.
Access to the Kubernetes API from the outside. Not only through provider identification systems, but just in case, through the service account token. Otherwise, if the hoster’s identification system breaks, you simply will not get into your cluster.
Restriction on IP addresses. As a rule, managed solutions expose the entire interface on which they listen to the Kubernetes API to the outside, to the Internet. And any attacker can try to hack this cluster – holes have already been found in Kubernetes that allowed sending special requests to the open API and gaining access. So it’s better if the provider has the ability to whitelist IPs.
The answer to the main question: what to choose
As we said at the beginning, there is no universal answer to this question – you still have to decide on your own. But if you have a small business, low loads and no separate team for Kubernetes, you can choose a managed solution. So you focus on deployment, and everything will be fine.
As soon as you grow up, the loads will become high and instead of three microservices you will have three dozen, you can recruit specialists and build your own self-hosted solution, configured exactly for you.