In this article, we will share our experience of deploying a robust and scalable installation of the popular single sign-on (SSO) solution – Keycloak in conjunction with Infinispan (for caching user metadata) on a Kubernetes cluster.
Keycloak and scope
Keycloak is an open-source project from Red Hat designed to manage authentication and authorization in applications running on WildFly application servers, JBoss EAP, JBoss AS, and other web servers. Keycloak simplifies the implementation of securing applications by providing them with an authorization backend with little or no additional code.
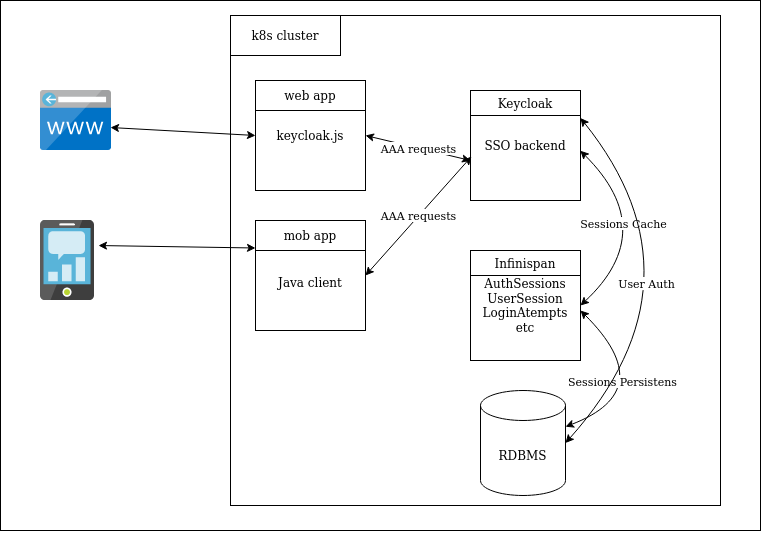
As a rule, Keycloak is installed on a separate virtual or dedicated WildFly application server. Users are authenticated once with Keycloak for all applications integrated with the solution. This way, after logging into Keycloak, users do not need to log in again to access another application. The same happens with the exit.
To store its data, Keycloak supports a number of the most popular relational database management systems: Oracle, MS SQL, MySQL, PostgreSQL. In our case, we used CockroachDB – a modern distributed DBMS (initially Open Source, and later – under BSL), which provides data consistency, scalability, and resilience to accidents. One of its nice features is protocol-level compatibility with PostgreSQL.
In addition, Keycloak actively uses caching in its work: user sessions, authorization, and authentication tokens, successful and unsuccessful authorization attempts are cached. By default, Infinispan is used to store all of this. We will dwell on it in more detail.
Infinispan
Infinispan is a scalable, highly available key-value storage platform written in Java and released under a free license (Apache License 2.0). Infinispan’s main application is distributed cache, but it is also used as KC storage in NoSQL databases.
The platform supports two launch methods: deploying as a stand-alone server / server cluster and using it as an embedded library to extend the functionality of the main application.
KC uses the built-in Infinispan cache by default. It allows you to configure distributed caches so that replication and roll-overs take place without downtime. Thus, even if we completely disable KC itself, and then bring it back up, it will not affect authorized users.
IS itself stores everything in memory, and in case of an overflow (or complete shutdown of IS), you can configure its data to be dumped to the database. In our case, this function is performed by CockroachDB.
Formulation of the problem
The client had already used the KC as a backend for authorizing his application but was worried about the stability of the solution and the safety of caches in case of accidents/deployments. Therefore, we had two tasks:
- Provide reliability/resilience to accidents, high availability.
- Save user data (sessions, tokens) in case of potential memory overflow.
Description of the infrastructure and architecture of the solution
Initially, KC was launched in 1 replica and with default caching settings, i.e. the built-in Infinispan was used, which kept everything in memory. The data source was the CockroachDB cluster.
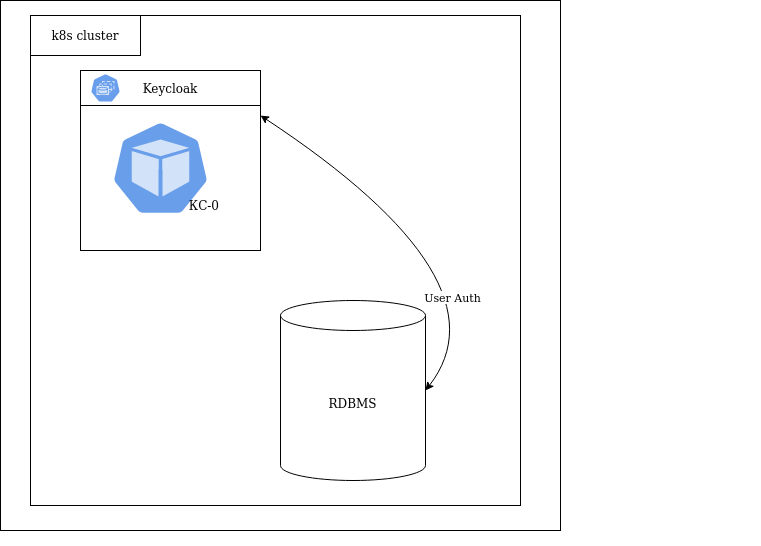
To ensure reliability, several KC replicas had to be deployed. Keycloak allows you to do this using several auto-discover mechanisms. In the first iteration, we made 3 replicas of KC using IS as a module/plugin:
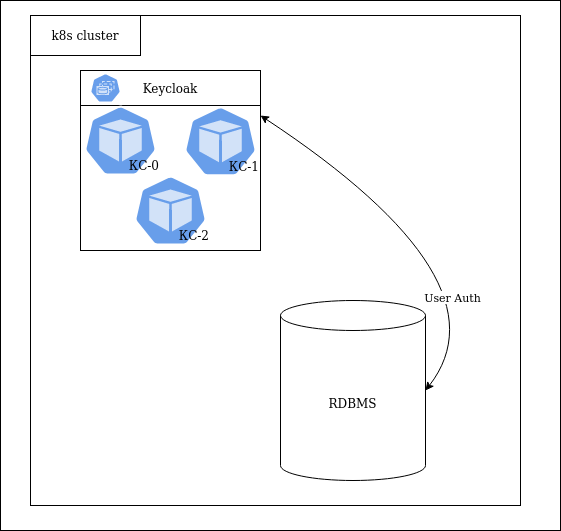
Unfortunately, IS used as a module did not provide enough options for configuring the behavior of caches (number of entries, amount of memory occupied, preemptive algorithms to persistent storage) and offered only the file system as persistent storage for data.
Therefore, in the next iteration, we deployed a separate Infinispan cluster and disabled the built-in IS module in the Keycloak settings:
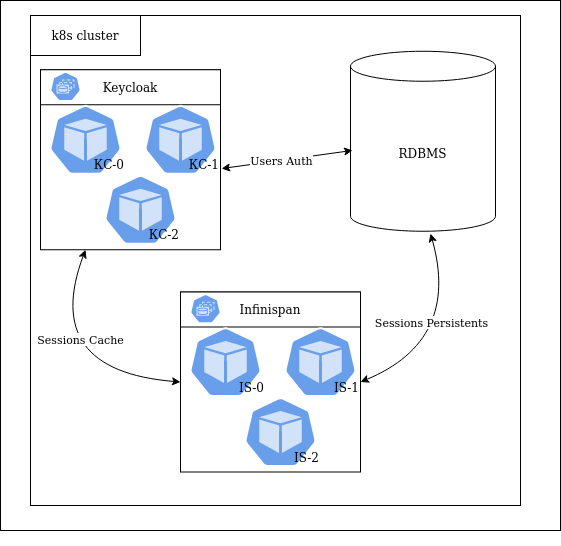
The solution was deployed to a Kubernetes cluster. Keycloak and Infinispan are launched in the same namespace, 3 replicas each. This Helm chart was taken as the basis for such an installation. CockroachDB was deployed in a separate namespace and shared with other components of the client application.
Practical implementation
1. Keycloak
KC supports several launch modes: standalone, standalone-ha, domain cluster, DC replication. The standalone-ha mode is ideal for launching because it is easy to add/remove replicas, the general config file is stored in ConfigMap, and the correctly chosen deployment strategy ensures the availability of nodes during software updates.
Although KC does not require persistent file storage (PV / PVC) and could choose the Deployment type, we use a StatefulSet. This is in order to set the hostname in the jboss.node.name Java variable when configuring host discovery based on DNS_PING. This variable must be less than 23 characters in length.
To configure KC is used:
- environment variables that set KC modes of operation (standalone, standalone-ha, etc.);
- configuration file
/opt/jboss/keycloak/standalone/configuration/standalone-ha.xml, which allows you to perform the most complete and accurate Keycloak configuration; JAVA_OPTSvariables that define the behavior of the Java application.
By default, KC starts from standalone.xml – this config is very different from the HA version. To get the configuration we need, add to values.yaml
# Additional environment variables for Keycloak
extraEnv: |
…
- name: JGROUPS_DISCOVERY_PROTOCOL
value: "dns.DNS_PING"
- name: JGROUPS_DISCOVERY_PROPERTIES
value: "dns_query={{ template "keycloak.fullname". }}-headless.{{ .Release.Namespace }}.svc.{{ .Values.clusterDomain }}"
- name: JGROUPS_DISCOVERY_QUERY
value: "{{ template "keycloak.fullname". }}-headless.{{ .Release.Namespace }}.svc.{{ .Values.clusterDomain }}"
After the first launch, you can get the required config from the pod with KC and, based on it, prepare .helm/templates/keycloak-cm.yaml:
$ kubectl -n keycloak cp keycloak-0:/opt/jboss/keycloak/standalone/configuration/standalone-ha.xml /tmp/standalone-ha.xml
After the file is received, the JGROUPS_DISCOVERY_PROTOCOL and JGROUPS_DISCOVERY_PROPERTIES variables can be renamed or deleted so that KC does not try to create this file on every redeploy.
Set JAVA_OPTS in .helm/values.yaml:
java:
_default: "-server -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jboss.byteman --add-exports=java.base/sun.nio.ch=ALL-UNNAMED --add-exports=jdk.unsupported/sun.misc=ALL-UNNAMED --add-exports=jdk.unsupported/sun.reflect=ALL-UNNAMED -Djava.awt.headless=true -Djboss.default.jgroups.stack=kubernetes -Djboss.node.name=${POD_NAME} -Djboss.tx.node.id=${POD_NAME} -Djboss.site.name=${POD_NAMESPACE} -Dkeycloak.profile.feature.admin_fine_grained_authz=enabled -Dkeycloak.profile.feature.token_exchange=enabled -Djboss.default.multicast.address=230.0.0.5 -Djboss.modcluster.multicast.address=224.0.1.106 -Djboss.as.management.blocking.timeout=3600"
For DNS_PING to work correctly, specify:
-Djboss.node.name=${POD_NAME}, -Djboss.tx.node.id=${POD_NAME} -Djboss.site.name=${POD_NAMESPACE} и -Djboss.default.multicast.address=230.0.0.5 -Djboss.modcluster.multicast.address=224.0.1.106
All other manipulations are performed with .helm/templates/keycloak-cm.yaml.
Base connection:
jdbc:postgresql://${env.DB_ADDR:postgres}/${env.DB_DATABASE:keycloak}${env.JDBC_PARAMS:}
postgresql
IdleConnections
${env.DB_USER:keycloak}
${env.DB_PASSWORD:password}
SELECT 1
true
60000
org.postgresql.xa.PGXADataSource
…
Cache settings:
true org.keycloak.cluster.infinispan.KeycloakHotRodMarshallerFactory
JGROUPS and DNS_PING settings:
${env.JGROUPS_DISCOVERY_QUERY}
...
${env.JGROUPS_DISCOVERY_QUERY}
...
Finally, we connect the external Infinispan:
Mount the prepared XML file into a container from ConfigMap .helm/templates/keycloak-cm.yaml:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: keycloak-stand
spec:
serviceName: keycloak-stand-headless
template:
spec:
containers:
image: registry.host/keycloak
name: keycloak
volumeMounts:
- mountPath: /opt/jboss/keycloak/standalone/configuration/standalone-ha.xml
name: standalone
subPath: standalone.xml
volumes:
- configMap:
defaultMode: 438
name: keycloak-stand-standalone
name: standalone
2. Infinispan
Configuring Infinispan is much easier than KC, since there are no steps to generate the required config file.
We get the default config /opt/infinispan/server/conf/infinispan.xml from the Docker image infinispan/server:12.0 and based on it we prepare .helm/templates/infinispan-cm.yaml.
The first step is to set up auto-discovery. To do this, we set the already familiar environment variables in .helm/templates/infinispan-sts.yaml:
env:
{{- include "envs" . | indent 8 }}
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: JGROUPS_DISCOVERY_PROTOCOL
value: "dns.DNS_PING"
- name: JGROUPS_DISCOVERY_PROPERTIES
value: dns_query={{ ( printf "infinispan-headless.keycloak-%s.svc.cluster.local" .Values.global.env ) }}
… and add the jgroups section to the XML config:
For Infinispan to work correctly with CockroachDB, we had to rebuild the Infinispan image, adding a new version of the PostgreSQL SQL driver to it. To build, we used the werf utility with such a simple werf.yaml:
---
image: infinispan
from: infinispan/server:12.0
git:
- add: /jar/postgresql-42.2.19.jar
to: /opt/infinispan/server/lib/postgresql-42.2.19.jar
shell:
setup: |
chown -R 185:root /opt/infinispan/server/lib/
Add the <data-source> section to the XML config:
value
In Infinispan, we must describe those caches that were created in KC with the distributed-cache type. For example offlineSessions:
We configure the rest of the caches in the same way.
Connecting the XML config is similar to what we considered Keycloak.
This completes the configuration of Keycloak and Infinispan.
Conclusion
This solution made it easy to scale the solution, adding either Keycloak nodes to handle incoming requests or Infinispan nodes to increase cache capacity as needed.
Since the delivery of this work to the client, no complaints and shortcomings have been identified during this period. Therefore, we can assume that the set goals have been achieved: we have received a stable, scalable solution for providing SSO.